Introduction
Natural Language Processing (NLP) has witnessed a significant boost with the advent of transfer learning. In this blog post, we explore ELMo Embeddings, a cutting-edge approach to word embeddings, leveraging a large unlabelled text corpus for enhanced sentiment analysis. We’ll delve into the implementation using TensorFlow and TensorFlow Hub.
Preparation
Let’s start by setting up the environment. Install and import the necessary libraries:
elmo_model = hub.Module("https://alpha.tfhub.dev/g# Preparation
!pip install tensorflow_hub
import tensorflow as tf
import tensorflow_hub as hub
from keras import backend
# Initializing ELMo model
elmo_model = hub.Module("https://alpha.tfhub.dev/google/elmo/2", trainable=True)
sess = tf.Session()
backend.set_session(sess)
sess.run(tf.global_variables_initializer())
sess.run(tf.tables_initializer())
oogle/elmo/2", trainable=True) sess = tf.Session() backend.set_session(sess) sess.run(tf.global_variables_initializer()) sess.run(tf.tables_initializer())Simple Embeddings
As a baseline, we’ll work with standard word embeddings. Download and load English word embeddings from Facebook Research’s MUSE project:
!wget https://s3.amazonaws.com/arrival/embeddings/wiki.multi.en.vec -O /tmp/wiki.multi.en.vecLoad the embeddings and create an embedding matrix:
# Code for loading and creating embedding m# Simple Embeddings
!wget https://s3.amazonaws.com/arrival/embeddings/wiki.multi.en.vec -O /tmp/wiki.multi.en.vec
# Loading and creating embedding matrix
# Code for loading embeddings and creating embedding matrix
atrixModels
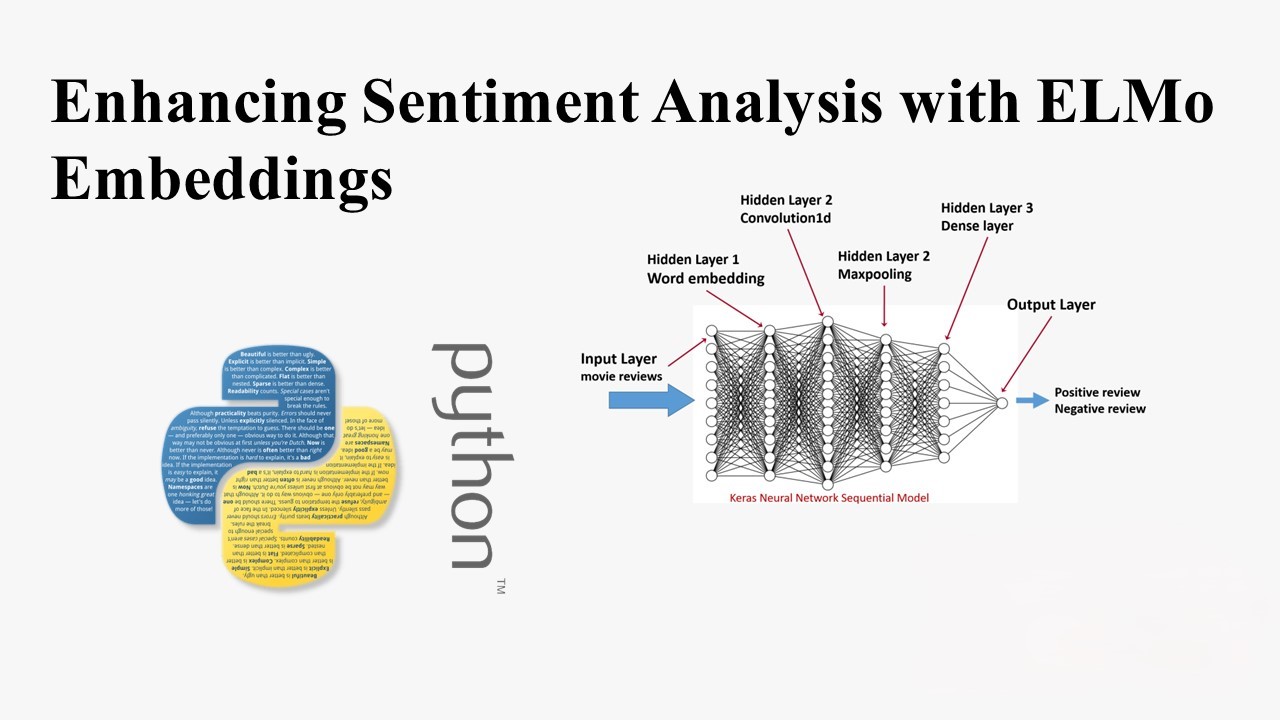
Basic Model
Define a basic sentiment analysis model with standard word embeddings:
# Basic Model
from keras.models import Sequential
from keras.layers import Dense, Embedding, Conv1D, MaxPooling1D, Flatten
from keras.optimizers import Adam
def create_basic_model():
model = Sequential()
model.add(Embedding(VOCABULARY_SIZE+INDEX_FROM-1, EMBEDDING_DIM, input_length=SEQ_LENGTH,
weights=[embedding_matrix_en], trainable=False))
model.add(Conv1D(filters=64, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPooling1D(pool_size=SEQ_LENGTH))
model.add(Flatten())
model.add(Dense(250, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
optimizer = Adam(lr=0.0001, decay=1e-3)
model.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
# Create the model
model_baseline = create_basic_model()
ELMo Model
Implement a sentiment analysis model using ELMo embeddings:
# ELMo Model
from keras.models import Model
from keras.layers import Input, Lambda, Concatenate
ELMO_EMBEDDING_DIM = 1024
def ElmoEmbedding(x):
y = elmo_model(tf.squeeze(x), signature="default", as_dict=True)["elmo"]
return y
def create_elmo_model():
token_sequence = Input(shape=(1,), dtype="string", name="elmo_input")
index_sequence = Input(shape=(SEQ_LENGTH,), name="standard_input")
embedding1 = Lambda(ElmoEmbedding, output_shape=(SEQ_LENGTH, ELMO_EMBEDDING_DIM,))(token_sequence)
embedding2 = Embedding(VOCABULARY_SIZE+INDEX_FROM-1, EMBEDDING_DIM, input_length=SEQ_LENGTH,
weights=[embedding_matrix_en], trainable=False)(index_sequence)
embedding = Concatenate()([embedding1, embedding2])
# Rest of the model architecture
# ...
return model
# Create the model
model_elmo = create_elmo_model()
Training
Train both models on a limited dataset:
# Code for training b# Training
def train_basic_model(model, X_train, y_train, X_val, y_val, X_test, y_test):
# Code for training basic model
# ...
def train_elmo_model(model, X_train, E_train, y_train, X_val, E_val, y_val, X_test, E_test, y_test):
# Code for training ELMo model
# ...
# Train the models
basic_accuracy = train_basic_model(model_baseline, X_train[:training_size], y_train[:training_size],
X_test[test_size:test_size+validation_size],
y_test[test_size:test_size+validation_size],
X_test[:test_size], y_test[:test_size])
elmo_accuracy = train_elmo_model(model_elmo, X_train[:training_size], E_train, y_train[:training_size],
X_test[test_size:test_size+validation_size],
E_val, y_test[test_size:test_size+validation_size],
X_test[:test_size], E_test, y_test[:test_size])
oth modelsResults
Compare the performance of the basic model and the ELMo model:
# Visualizing Results
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
# Creating a DataFrame for accuracies
accuracies = pd.DataFrame({'basic': basic_accuracies, 'elmo': elmo_accuracies})
# Plotting boxplot
plt.rcParams['figure.figsize'] = (10, 6)
accuracies.boxplot()
plt.title('Comparison of Basic and ELMo Models')
plt.ylabel('Accuracy')
plt.show()
# Pair plot
plt.scatter(np.zeros(len(basic_accuracies)), basic_accuracies, label='Basic Model')
plt.scatter(np.ones(len(elmo_accuracies)), elmo_accuracies, label='ELMo Model')
for i in range(len(basic_accuracies)):
plt.plot([0, 1], [basic_accuracies[i], elmo_accuracies[i]], c='k')
plt.xticks([0, 1], ['Basic', 'ELMo'])
plt.title('Pair Plot of Model Accuracies')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
Conclusion
In this experiment, we explored the impact of ELMo embeddings on sentiment analysis. The ELMo model exhibited improved accuracy and consistency compared to the basic model. Transfer learning, especially with advanced embeddings like ELMo, proves to be a valuable asset in NLP tasks.
Feel free to experiment further with larger datasets and fine-tuning options to unlock the full potential of ELMo embeddings in your NLP projects.
Leave a Reply