Category: Machine Learning
-
Understanding CIFAR-10 Dataset and K-Nearest Neighbors (KNN) Classifier
In this blog post, we’ll explore the CIFAR-10 dataset and how to use the K-Nearest Neighbors (KNN) algorithm to classify images from this dataset. CIFAR-10 is a well-known dataset in the field of machine learning and computer vision, consisting of 60,000 32×32 color images in 10 classes, with 6,000 images per class. Loading and Preprocessing…
-
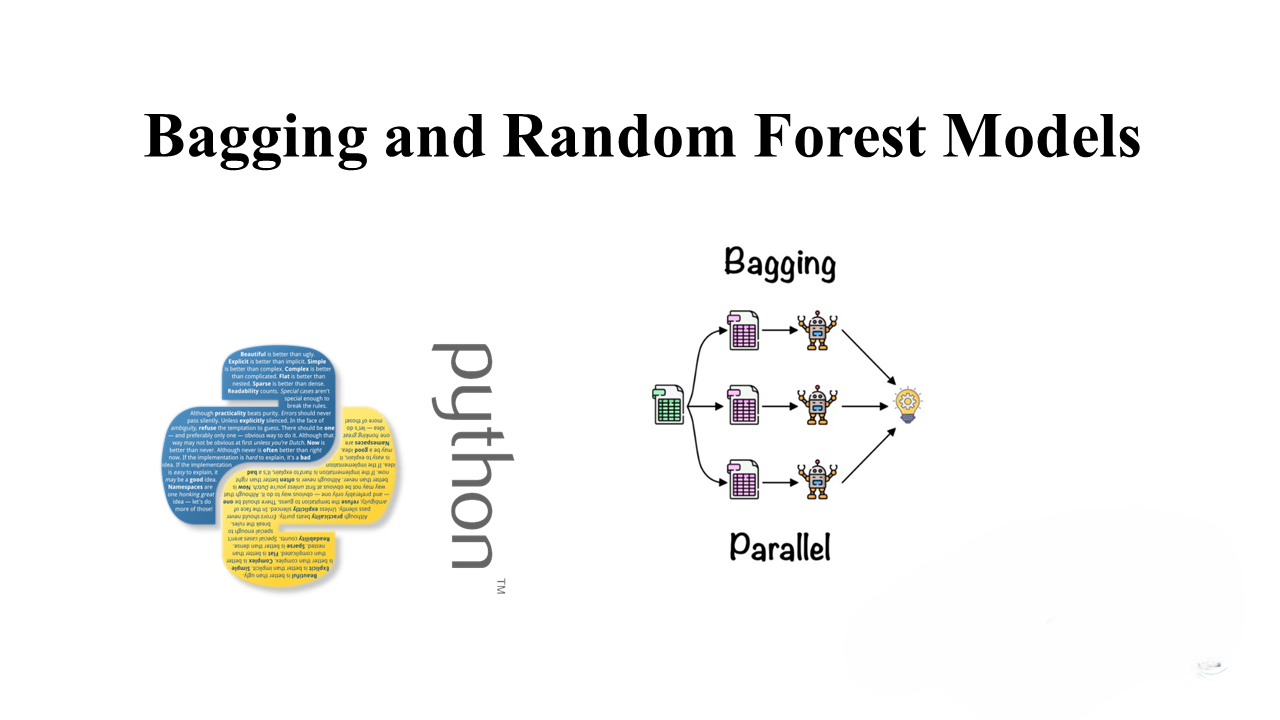
Understanding Bagging and Random Forest Models
Ensemble methods are powerful techniques that combine multiple weak learners to improve predictive performance. One popular ensemble method is bagging, which aggregates the predictions of multiple models trained on subsamples of the data. Random Forest, a widely used algorithm, employs bagging with decision trees to produce robust and scalable models. Introduction In this blog post,…
-
Mastering Linear Models: Regression, Classification, and Beyond
Introduction: Linear models play a fundamental role in the field of machine learning, providing a versatile toolkit for both regression and classification tasks. In this comprehensive guide, we’ll delve into various aspects of linear models, exploring techniques for regression, classification, and addressing challenges such as outliers and non-linear relationships. Buckle up as we journey through…
-
Understanding Model Selection & Evaluation
Model selection and evaluation are crucial steps in the machine learning pipeline. It involves choosing the best model for a given task, tuning hyperparameters, and assessing the model’s performance. In this blog post, we will explore several aspects of model selection and evaluation, including cross-validation, hyperparameter tuning, model persistence, validation curves, and learning curves. 1.…
-
Composite Estimators using scikit-learn: A Comprehensive Guide
Agenda 1. Introduction to Composite Estimators Composite Estimators in scikit-learn involve connecting one or more transformers with estimators to create a comprehensive model. These composite transformers are implemented using the Pipeline class, while FeatureUnion is used to concatenate the output of transformers to create derived features. Pipelines enhance code reusability and modularity in machine learning…
-
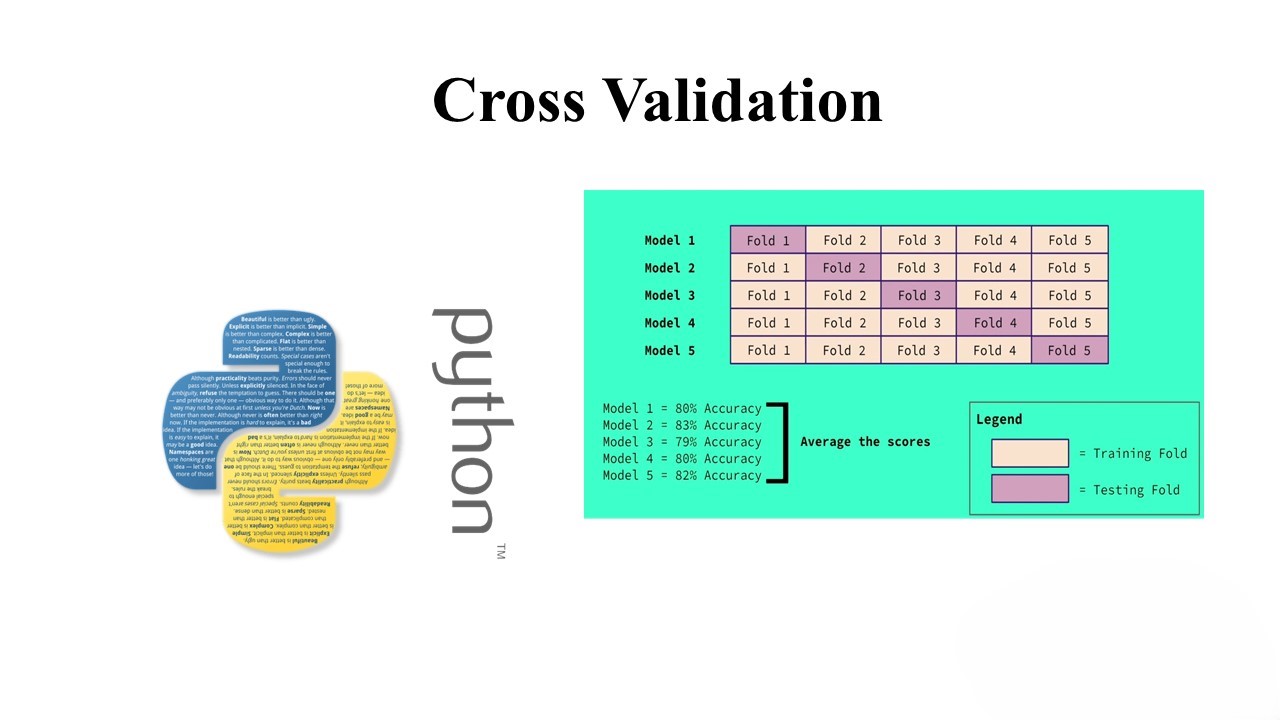
Understanding Model Selection with Cross Validation
Introduction: In machine learning, model selection plays a crucial role in creating models that generalize well to new, unseen data. One common approach to model selection is through cross-validation, a resampling method that helps estimate the performance of a model on different subsets of the dataset. This blog post will explore the concepts of cross-validation…
-
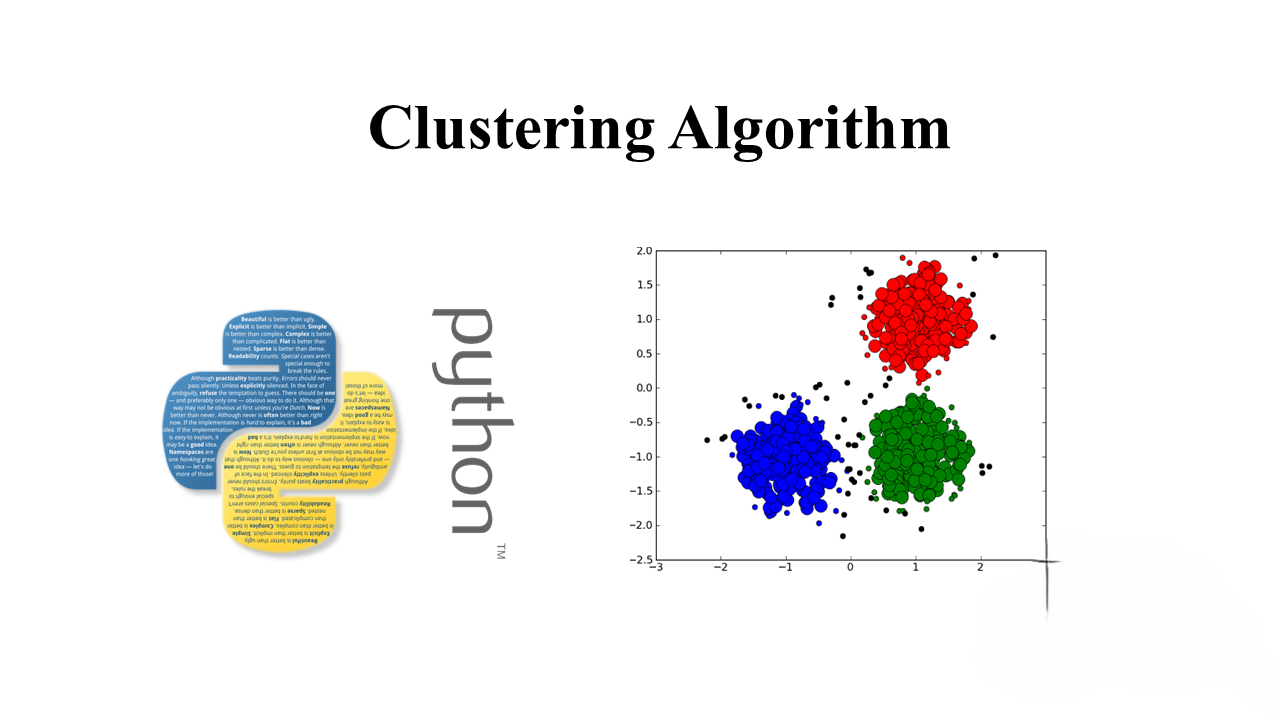
Unraveling Cluster Analysis: A Comprehensive Guide
Introduction to Unsupervised Learning Unsupervised learning is a fascinating domain in machine learning that involves drawing inferences from unlabeled datasets. Unlike supervised learning, where the model learns from labeled data, unsupervised learning explores relationships within data without predefined categories. One of the primary methods in unsupervised learning is clustering, which uncovers hidden patterns or groups…
-

Image Processing and Object Comparison using Python – Part 3
Practical Applications and Advanced Concepts Introduction: Welcome to the third and final part of our tutorial on Image Processing and Object Comparison using Python. In this section, we’ll explore practical applications and advanced concepts that build upon the knowledge gained in the previous parts. By the end of this tutorial, you’ll be equipped with the…
-

Image Processing and Object Comparison using Python – Part 2
Image Comparison and Similarity Measurement Introduction: Welcome to the second part of our tutorial on Image Processing and Object Comparison using Python. In this section, we’ll delve into image comparison and explore techniques for measuring the similarity between two images. Understanding these methods is crucial for various applications, such as image retrieval, object recognition, and…
-

Exploring Named Entity Recognition with Conditional Random Fields
Named Entity Recognition (NER) is a fundamental task in natural language processing that involves identifying and classifying entities, such as names of people, organizations, and locations, within a text. NER plays a crucial role in various applications, including information retrieval, question answering, and text summarization. In this blog post, we’ll dive into the world of…