Category: Machine Learning
-

Extracting and Analyzing Car Listings from OLX – A Web Scraping Adventure
Introduction Web scraping is a powerful technique to extract valuable information from websites. In this blog post, we explore the process of scraping car listings from OLX, focusing on the Tamil Nadu region. We will cover topics such as web scraping, data cleaning, and parsing, providing both code snippets and detailed explanations. Web Scraping OLX…
-

Visualizing Data for Classification
In this lab, we’ll explore the German bank credit dataset to understand relationships for a classification problem. Unlike regression problems where the label is a continuous variable, classification problems involve categorical labels. We aim to visually explore the data to identify features useful in predicting customers with bad credit. Load and Prepare the Dataset Let’s…
-
Unveiling the Power of Principal Component Analysis (PCA)
Introduction In the vast landscape of machine learning, we’ve delved into supervised learning methods for predicting labels based on labeled training data. Now, let’s embark on a journey into the realm of unsupervised learning. Here, the focus is on algorithms that uncover intriguing aspects of data without relying on any known labels. One such workhorse…
-

Exploring Strategies for Handling Imbalanced Classes in Machine Learning
Imbalanced class distribution poses a significant challenge in machine learning, where the occurrence of certain events is rare compared to others. In this tutorial, we delve into various strategies to address this issue, exploring oversampling, undersampling, pipeline integration, algorithm awareness, and anomaly detection. By understanding and implementing these techniques, we aim to build more robust…
-
Essential Pandas for Machine Learning: Part 2
Pandas is a powerful and versatile open-source library for data analysis in Python. It provides easy-to-use data structures like Series and DataFrames, making it an essential tool for handling and manipulating data in machine learning projects. In this blog post, we will explore some key aspects of Pandas that are crucial for anyone working in…
-
Essential Pandas for Machine Learning: Part 1
Pandas is a powerful and versatile open-source library for data analysis in Python. It provides easy-to-use data structures like Series and DataFrames, making it an essential tool for handling and manipulating data in machine learning projects. In this blog post, we will explore some key aspects of Pandas that are crucial for anyone working in…
-
Understanding Support Vector Machines (SVMs) in Depth
Support Vector Machines (SVMs) are a powerful class of supervised algorithms used for both classification and regression tasks. In this blog post, we will delve into the intuition behind SVMs and their application in solving classification problems. Motivation To begin, let’s consider a simple classification task with well-separated classes. We’ll generate some synthetic data with…
-
Anomaly Detection with Machine Learning
Introduction: Anomaly detection is a crucial technique in data analysis, with applications ranging from fraud detection to network security. It involves identifying unusual data points that deviate significantly from the majority of observations. In this tutorial, we will explore the concept of anomaly detection and demonstrate how to implement it using Python. Specifically, we’ll use…
-

Predicting Website Traffic with Multiple Linear Regression: A Step-by-Step Guide
Introduction:In today’s digital age, understanding website traffic is crucial for businesses and website owners. Inthis blog post, we’ll explore how to build a multiple linear regression model to predict website trafficbased on various factors like marketing spend, social media activity, and SEO efforts.Step 1: Collect and Prepare the Dataset:To begin, you need a dataset that…
-
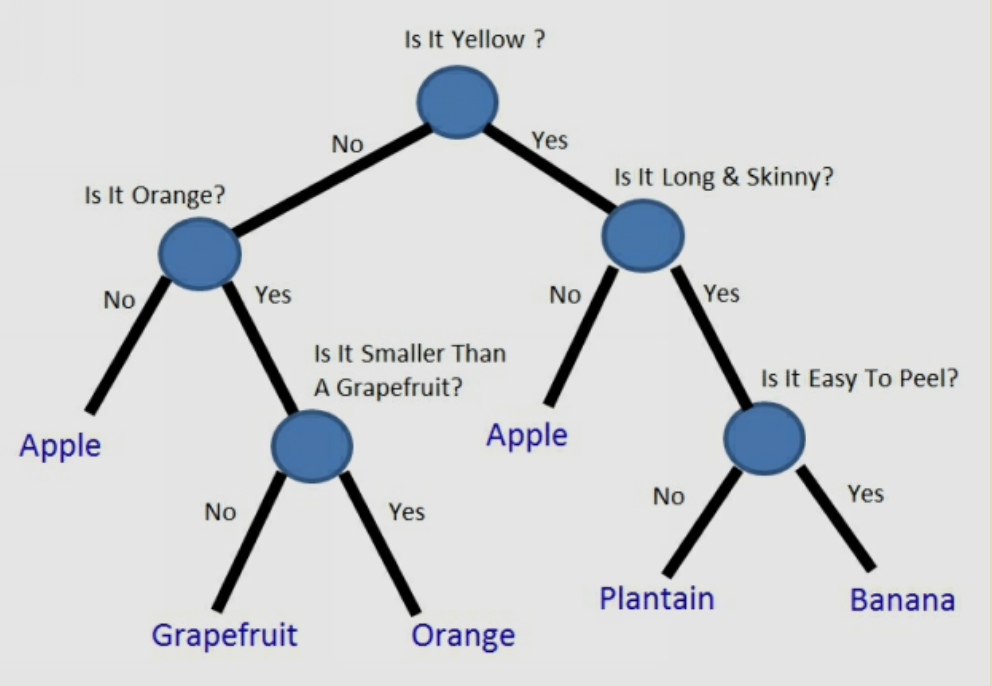
How Decision Tree works
Decision Tree:* Decision Tree is a non-parametric supervised learning method for regression & classification.* It”s similar to playing “dumb charades”.* A good algorithm will have less & right questions compared to not-so-good one.* The nodes are questions & leafs are prediction. Decision Tree Algorithm:* Decision Tree is based on CART which is advancement of ID3,…