Pandas is a powerful and versatile open-source library for data analysis in Python. It provides easy-to-use data structures like Series and DataFrames, making it an essential tool for handling and manipulating data in machine learning projects. In this blog post, we will explore some key aspects of Pandas that are crucial for anyone working in the field of machine learning.
Agenda
Let’s break down the agenda for this Pandas tutorial:
- Introduction to Pandas
- Understanding Series & DataFrames
- Loading CSV, JSON
- Connecting databases
- Descriptive Statistics
- Accessing subsets of data – Rows, Columns, Filters
- Handling Missing Data
- Dropping rows & columns
1. Introduction to Pandas
Pandas is a high-performance, easy-to-use open-source library for data analysis. It allows you to create tabular formats of data from different sources such as CSV, JSON, and databases. With utilities for descriptive statistics, aggregation, handling missing data, and database operations like merge and join, Pandas is a fast, programmable, and efficient alternative to traditional spreadsheets.
import pandas as pd
import numpy as np

2. Understanding Series & DataFrames
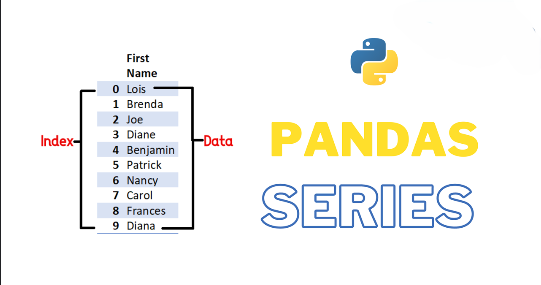
Pandas represents data using two primary data structures: Series and DataFrames. A Series represents a single column, while a DataFrame is a combination of multiple columns forming a table.
ser1 = pd.Series(data=[1, 2, 3, 4, 5], index=list('abcde'))
ser2 = pd.Series(data=[11, 22, 33, 44, 55], index=list('abcde'))
df = pd.DataFrame({'A': ser1, 'B': ser2})
3. Loading CSV, JSON
Pandas makes it easy to load data from various sources. In this example, we load HR data from a CSV file and movie data from a JSON file.
hr_data = pd.read_csv('https://raw.githubusercontent.com/zekelabs/data-science-complete-tutorial/master/Data/HR_comma_sep.csv.txt')
movie_data = pd.read_json('https://raw.githubusercontent.com/zekelabs/data-science-complete-tutorial/master/Data/movie.json.txt')4. Connecting Databases
Pandas can also connect to databases and fetch data. Here’s an example using SQLite:
import sqlite3
con = sqlite3.connect('Data/database.sqlite')
pd.read_sql_query("SELECT * FROM Reviews LIMIT 5", con)
5. Descriptive Statistics
Pandas provides various functions for understanding data. For instance, you can use the describe() function to get descriptive statistics of a DataFrame.
hr_data.describe()
6. Accessing Subsets of Data – Rows, Columns, Filters
Accessing specific parts of your data is crucial. Pandas offers multiple ways to achieve this, including selecting columns by name or accessing rows by index.
cat_cols_data = hr_data.select_dtypes('object')
hr_data[['satisfaction_level', 'last_evaluation', 'number_project']].head()
7. Handling Missing Data
Dealing with missing data is a common challenge. Pandas provides methods to filter or fill missing values.
movie_data.dropna(subset=['Adam Cohen']).info()
8. Dropping Rows & Columns
Sometimes, dropping unnecessary rows or columns is necessary for better analysis.
titanic_data.drop(['Cabin'], axis=1, inplace=True)
Conclusion
Pandas is an indispensable tool for any data scientist or machine learning practitioner. In this tutorial, we’ve covered just a fraction of what Pandas can offer. As you delve deeper into data analysis and machine learning, mastering Pandas will undoubtedly enhance your productivity and analytical capabilities.
Stay tuned for more tutorials on advanced Pandas functionalities!
Leave a Reply