
Imbalanced class distribution poses a significant challenge in machine learning, where the occurrence of certain events is rare compared to others. In this tutorial, we delve into various strategies to address this issue, exploring oversampling, undersampling, pipeline integration, algorithm awareness, and anomaly detection. By understanding and implementing these techniques, we aim to build more robust and unbiased models.

Introduction
Imbalanced classes occur when one class dominates the dataset, leading to biased models that perform poorly on the minority class. This is a common scenario in fraud detection, medical diagnosis, and other real-world applications. The consequences of ignoring imbalanced classes include inaccurate predictions and skewed model evaluations. Therefore, it’s crucial to explore effective strategies to handle this issue.
1. Imbalanced Classes & Impact
To illustrate the impact of imbalanced classes, let’s generate a dataset with skewed class distribution.
# Generating imbalanced dataset
n_samples_1 = 1000 n_samples_2 = 100 centers = [[0.0, 0.0], [2.0, 2.0]]
clusters_std = [1.5, 0.5] X, y = make_blobs(n_samples=[n_samples_1, n_samples_2], centers=centers, cluster_std=clusters_std, random_state=0, shuffle=False)
# Visualizing the dataset
plt.scatter(X[:,0], X[:,1], s=10, c=y)As shown in the plot, the decision boundary of a classification algorithm is impacted by this imbalance.
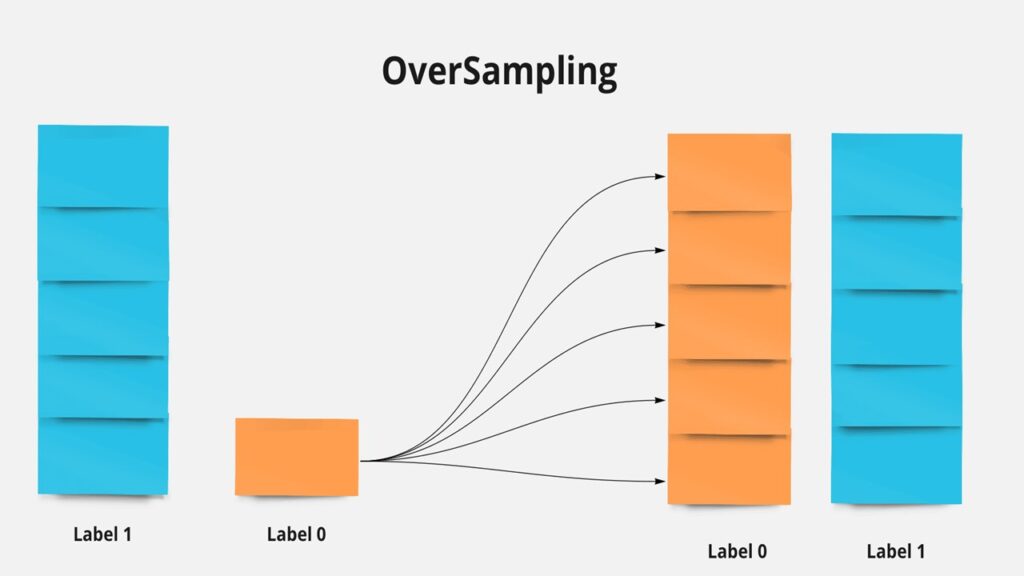
2. OverSampling
One way to tackle imbalanced classes is to oversample the minority class. The imbalanced package provides various sampling techniques.
from imblearn.over_sampling import RandomOverSampler, SMOTE, ADASYN
# Using RandomOverSampler
ros = RandomOverSampler(random_state=0) X_resampled, y_resampled = ros.fit_sample(X, y)
plt.scatter(X_resampled[:,0], X_resampled[:,1], c=y_resampled, s=10)Similar examples can be demonstrated with SMOTE (Synthetic Minority Oversampling Technique) and ADASYN.
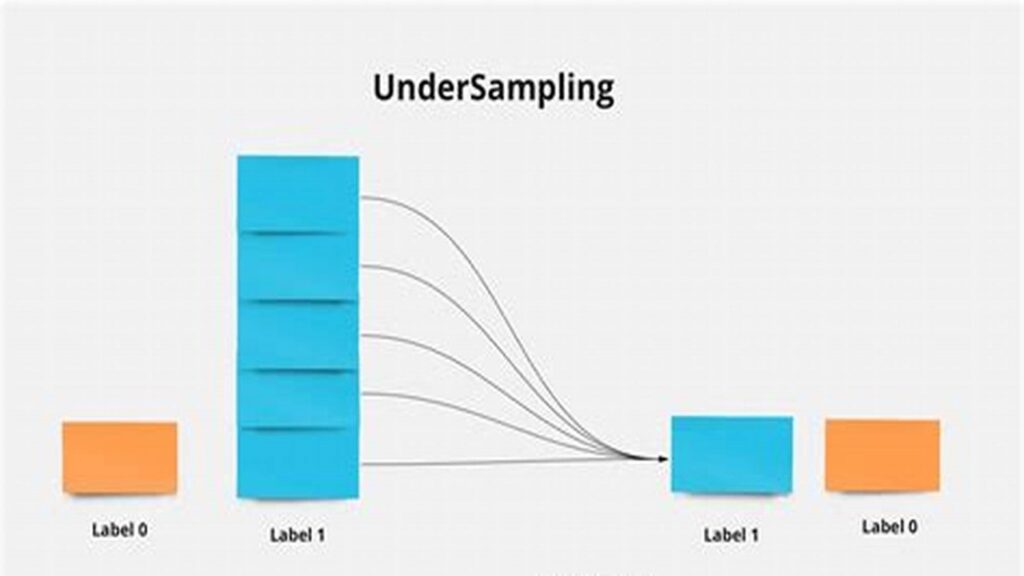
3. UnderSampling
Another approach is to reduce the data of the over-represented class.
from imblearn.under_sampling import RandomUnderSampler, ClusterCentroids
# Using RandomUnderSampler rus = RandomUnderSampler(random_state=0) X_resampled, y_resampled = rus.fit_sample(X, y)
plt.scatter(X_resampled[:,0], X_resampled[:,1], c=y_resampled, s=10)The ClusterCentroids method can be employed for generating representative data using k-means.
4. Connecting Sampler to Pipelines
To integrate sampling techniques into a machine learning pipeline, the imblearn.pipeline module is used.
from imblearn.pipeline import make_pipeline
# Creating pipelines with different samplers
pipeline1 = make_pipeline(RandomOverSampler(), SVC(kernel='linear'))
pipeline2 = make_pipeline(RandomUnderSampler(), SVC(kernel='linear'))
# Fitting pipelines for pipeline in [pipeline1, pipeline2]:
pipeline.fit(X, y) pred = pipeline.predict(X)
print(confusion_matrix(y_pred=pred, y_true=y))5. Making Learning Algorithms Aware of Class Distribution
Many classification algorithms provide a class_weight parameter to handle imbalanced classes internally.
from sklearn.svm import SVC
# Without balanced class weights
svc = SVC(kernel='linear')
svc.fit(X, y)
pred = svc.predict(X)
print(confusion_matrix(y_pred=pred, y_true=y))
# With balanced class weights
svc = SVC(kernel='linear', class_weight='balanced')
svc.fit(X, y)
pred = svc.predict(X)
print(confusion_matrix(y_pred=pred, y_true=y))6. Anomaly Detection
Considering under-represented data as anomalies and using anomaly detection techniques is an alternative strategy.
from sklearn.cluster import MeanShift
# Generating a new imbalanced dataset
n_samples_1 = 1000 n_samples_2 = 100 centers = [[0.0, 0.0], [3.5, 3.5]]
clusters_std = [1.5, 0.5] X, y = make_blobs(n_samples=[n_samples_1,
n_samples_2], centers=centers, cluster_std=clusters_std, random_state=0, shuffle=False)
# Using MeanShift for anomaly detection
ms = MeanShift(bandwidth=2, n_jobs=-1)
ms.fit(X)
pred = ms.predict(X)
plt.scatter(X[:,0], X[:,1], s=10, c=pred)These techniques offer a robust way to handle imbalanced classes, ensuring machine learning models provide more accurate and fair predictions across different classes.
Conclusion
Dealing with imbalanced classes is a critical aspect of building fair and accurate machine learning models. This tutorial has provided a comprehensive exploration of various strategies, ranging from oversampling and undersampling to pipeline integration, algorithm awareness, and anomaly detection. By incorporating these techniques into their workflows, data scientists can enhance model robustness and ensure better performance across all classes in imbalanced datasets. Handling imbalanced classes is an ongoing challenge, and staying informed about evolving techniques is crucial for the advancement of machine learning applications.
Leave a Reply