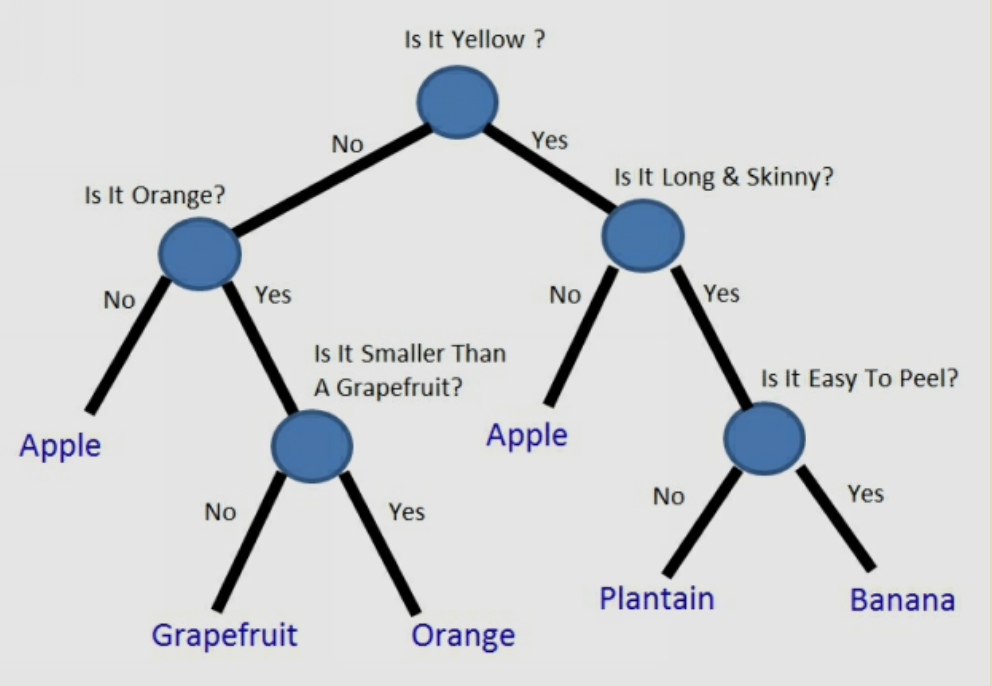
Decision Tree:
* Decision Tree is a non-parametric supervised learning method for regression & classification.
* It”s similar to playing “dumb charades”.
* A good algorithm will have less & right questions compared to not-so-good one.
* The nodes are questions & leafs are prediction.
Decision Tree Algorithm:
* Decision Tree is based on CART which is advancement of ID3, developed in 1986 by Ross Quinlan.
* ID3 works when feature data & target data both are categorical in nature.
* C4.5 is an advancement of ID3, it coverts continues features into categorical features. Then, proceeds with ID3.
* CART is based on C4.5, with slight advancement of “target can be continues”.
* scikit-learn decision trees are based on CART.
Criterion of creating Decision Tree:
1. Entropy – Objective of CART is to maximize information gain in each split.
2. Gini Impurity – If classes are mixed, gini impurity is maximul
Both the approaches, yields almost same results. We will discuss algorithm using Entropy.
Information Gain:
* The information gain is based on the decrease in entropy after a dataset is split on an attribute.
* Constructing a decision tree is all about finding attribute that returns the highest information gain (i.e., the most homogeneous branches).
* Gain(S, A) = Entropy(S) – ∑ [ p(S|A) . Entropy(S|A) ]
* We intend to choose the attribute, splitting by which information gain will be the most.
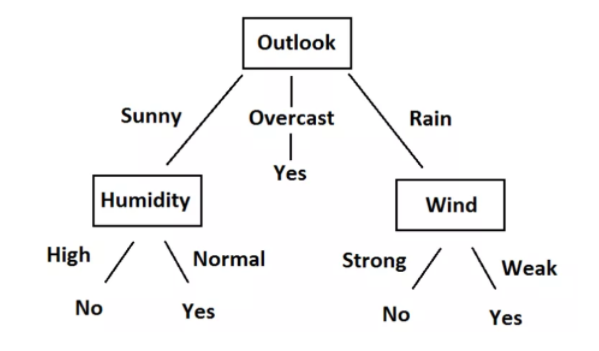
Let us take the tennis play data to understand the decision tree algorithm better. The below image is the decision tree for the tennis play data.
Step 1: Import necessary Packages.
Step 2: Load the dataset.
Step 3: Calculate the entropy for the play attribute.(There are 9 yes and 5 no in the play column)
Step 4: To find the root node, calculate information gain on all attributes. Let us start with outlook attribute. There are 2 yes and 3 no for sunny outlook, 3 yes and 2 no for rainy outlook. Overcast outlook is a homogeneous data, so entropy=0.
Step 5: Calculate information gain for rest of the attributes(temp, humidity, windy)
Step 6: Conclude the root node and repeat from step 4 to split the tree further.
import pandas as pd
import numpy as np
play_data = pd.read_csv("https://raw.githubusercontent.com/cogxta/datasets/main/tennis_data.csv")
print("Tennis Play Data");print("");print(play_data);print("")
Entropy_Play = -(9/14)*np.log2(9/14) -(5/14)*np.log2(5/14)
print("Entrophy of play: ");print(Entropy_Play);print("")
Entropy_Play_Outlook_Sunny =-(3/5)*np.log2(3/5) -(2/5)*np.log2(2/5)
Entropy_Play_Outlook_Rainy = -(2/5)*np.log2(2/5) - (3/5)*np.log2(3/5)
outlook_gain = Entropy_Play - (5/14)*Entropy_Play_Outlook_Sunny - (4/14)*0 - (5/14) * Entropy_Play_Outlook_Rainy
print("Information gain on outlook:");print(outlook_gain);print("")
Entropy_Play_temp_hot =-(2/4)*np.log2(2/4) -(2/4)*np.log2(2/4)
Entropy_Play_temp_mild = -(4/6)*np.log2(4/6) - (2/6)*np.log2(2/6)
Entropy_Play_temp_cool = -(3/4)*np.log2(3/4) - (1/4)*np.log2(1/4)
temp_gain = Entropy_Play - (4/14)*Entropy_Play_temp_hot - (6/14)*Entropy_Play_temp_mild - (4/14)*Entropy_Play_temp_cool
print("Information gain on Temperature:");print(temp_gain);print("")
Entropy_Play_humidity_high =-(3/7)*np.log2(3/7) -(4/7)*np.log2(4/7)
Entropy_Play_humidity_normal = -(6/7)*np.log2(6/7) - (1/7)*np.log2(1/7)
humidity_gain = Entropy_Play - (7/14)*Entropy_Play_humidity_high - (7/14)*Entropy_Play_humidity_normal
print("Information gain on Humidity: ");print(humidity_gain);print("")
Entropy_Play_windy_true =-(3/6)*np.log2(3/6) -(3/6)*np.log2(3/6)
Entropy_Play_windy_false = -(6/8)*np.log2(6/8) - (2/8)*np.log2(2/8)
windy_gain = Entropy_Play - (6/14)*Entropy_Play_windy_true - (8/14)*Entropy_Play_windy_false
print("Information gain on Windy: ");print(windy_gain);print("")
Leave a Reply