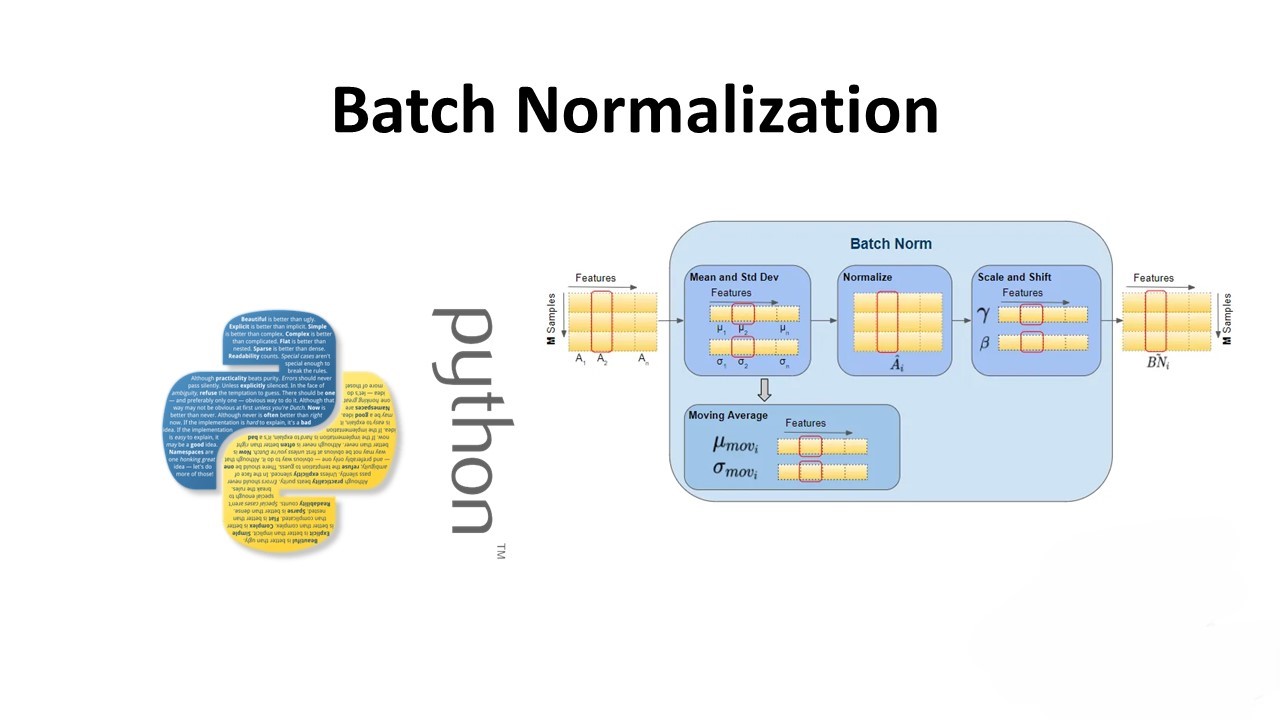
Batch Normalization (BN) is a technique used in deep learning to improve the training of deep neural networks by reducing the internal covariate shift problem. This problem occurs when the distribution of the inputs to each layer of the network changes during training, making it difficult to train the network effectively. BN addresses this issue by normalizing the inputs to each layer to have zero mean and unit variance, which helps in stabilizing and accelerating the training process.
Understanding Batch Normalization
To understand how Batch Normalization works, let’s consider a typical deep neural network with multiple layers. During training, as the network learns the weights and biases, the distribution of the input to each layer changes. This change in distribution, known as covariate shift, can slow down the training process and make it difficult for the network to converge to a good solution.
Batch Normalization addresses this issue by normalizing the input to each layer. This is done by computing the mean and variance of the inputs over a mini-batch of data and then normalizing the inputs using these statistics. Mathematically, the normalization is performed as follows:
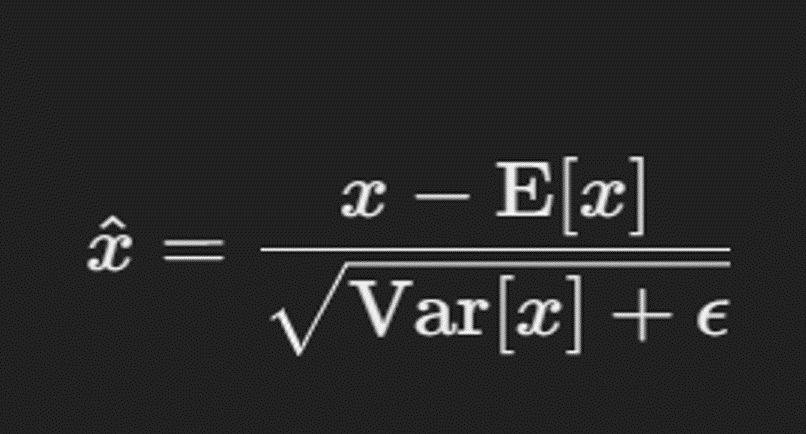
where (x) is the input to the layer, (\text{E}[x]) is the mean of the input, (\text{Var}[x]) is the variance of the input, and (\epsilon) is a small constant added for numerical stability. The normalized input (\hat{x}) is then scaled and shifted by learnable parameters (\gamma) and (\beta) to obtain the final output of the Batch Normalization layer:
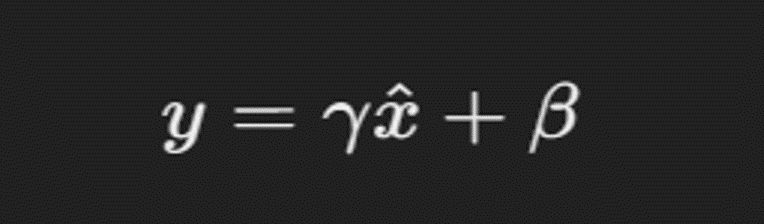
Implementing Batch Normalization
In TensorFlow, Batch Normalization can be easily implemented using the BatchNormalization layer. Here’s a simple example of how Batch Normalization can be added to a deep neural network using TensorFlow:
import tensorflow as tf
from tensorflow.keras.layers import Dense, BatchNormalization, Activation
from tensorflow.keras.models import Sequential
# Define the model
model = Sequential()
model.add(Dense(64, input_shape=(784,)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(10))
model.add(Activation('softmax'))
# Compile the model
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Train the model
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_val, y_val))In this example, a BatchNormalization layer is added after the Dense layer to normalize the inputs before applying the activation function. The model is then compiled and trained using the standard TensorFlow workflow.
Benefits of Batch Normalization
Batch Normalization offers several benefits for training deep neural networks:
- Faster Convergence: By reducing the internal covariate shift, Batch Normalization helps the network converge faster, reducing the number of training iterations required.
- Improved Gradient Flow: Normalizing the inputs helps maintain a more stable gradient flow, which can lead to better performance and more stable training.
Conclusion
Batch Normalization is a powerful technique for improving the training of deep neural networks. By normalizing the inputs to each layer, it helps in reducing the training time and improving the overall performance of the network. Consider using Batch Normalization in your deep learning projects to accelerate training and improve performance.
For a more detailed explanation and practical examples of Batch Normalization, check out my blog post on Batch Normalization in Deep Learning.
Leave a Reply