Tag: #DataScience
-
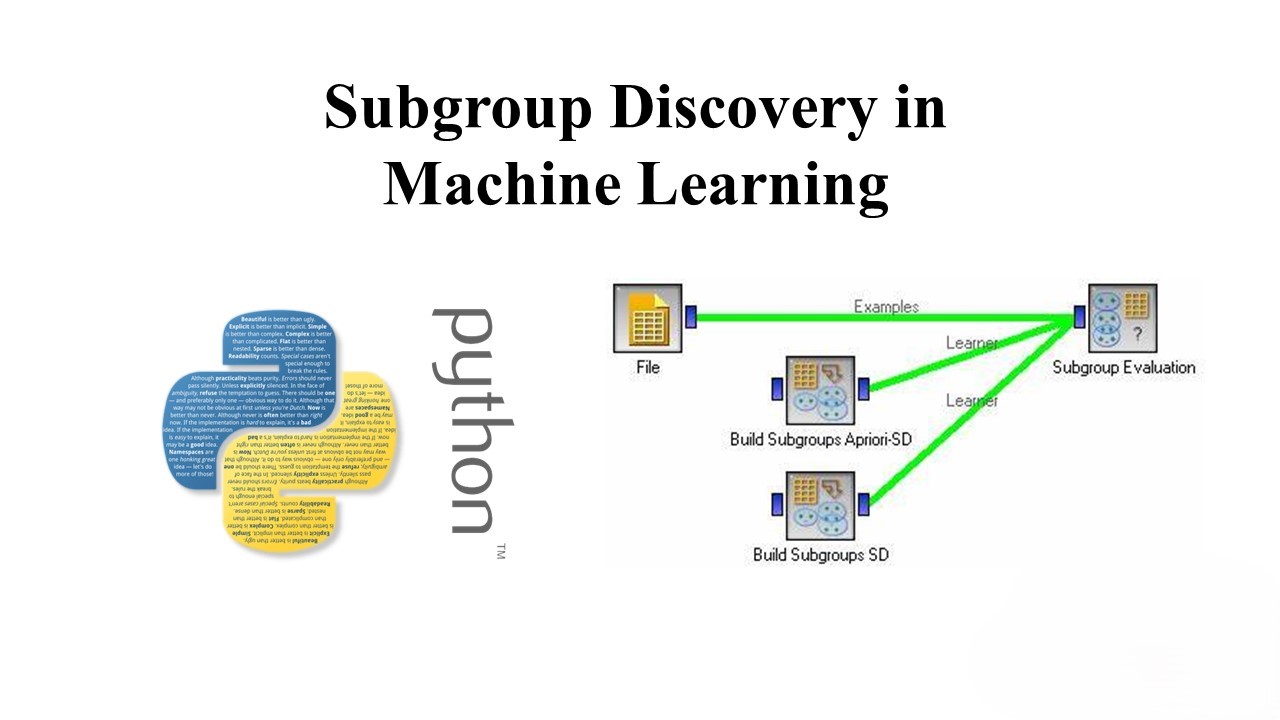
A Guide to Subgroup Discovery in Machine Learning
In the vast landscape of machine learning, uncovering hidden patterns in data is often the key to unlocking valuable insights. One powerful technique for achieving this is subgroup discovery, a method that focuses on identifying subsets of data that exhibit unique or interesting behavior. In this blog post, we’ll explore the concept of subgroup discovery…
-
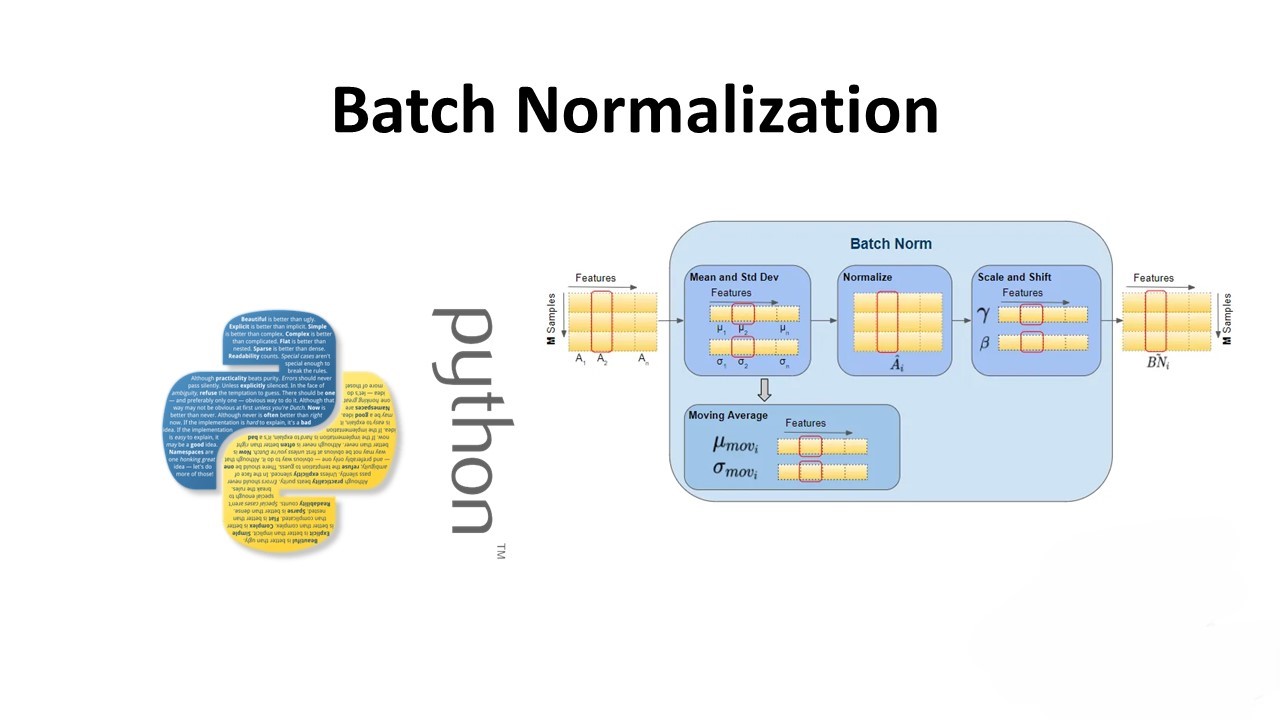
Optimizing Deep Learning: A Comprehensive Guide to Batch Normalization
Batch Normalization (BN) is a technique used in deep learning to improve the training of deep neural networks by reducing the internal covariate shift problem. This problem occurs when the distribution of the inputs to each layer of the network changes during training, making it difficult to train the network effectively. BN addresses this issue…
-
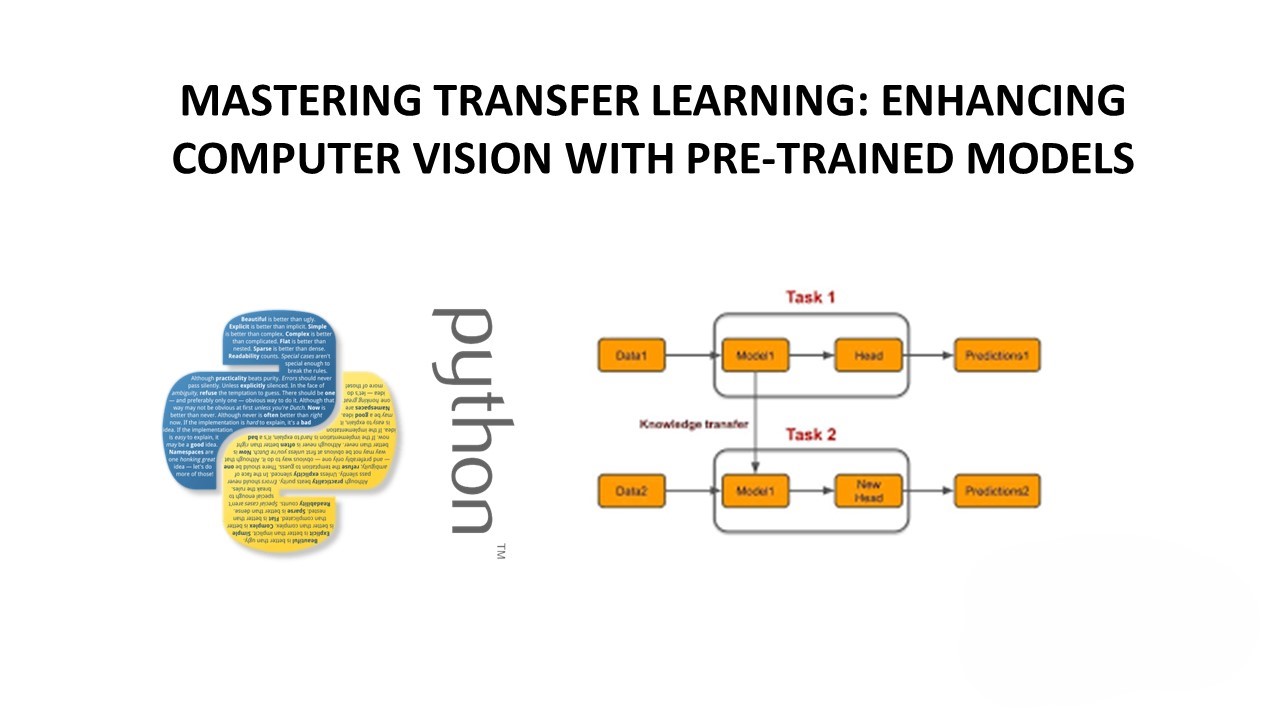
Mastering Transfer Learning: Enhancing Computer Vision with Pre-Trained Models
Transfer learning is a powerful technique in the field of deep learning, especially in computer vision, where it allows us to leverage pre-trained models to solve new tasks with limited data. In this blog post, we’ll explore transfer learning in the context of computer vision and demonstrate how it can be implemented using Python and…
-
Sentiment Analysis: Unveiling the Power of Text Analysis
In the era of big data, understanding customer sentiment is crucial for businesses to make informed decisions. Sentiment analysis, also known as opinion mining, is a powerful technique that helps businesses extract valuable insights from text data. Whether it’s understanding customer feedback, monitoring social media chatter, or analyzing product reviews, sentiment analysis can provide invaluable…
-
Exploring the Statistical Foundations of ARIMA Models
By Kishore Kumar K In the realm of time series analysis, ARIMA (AutoRegressive Integrated Moving Average) models stand out as a powerful tool for forecasting. Understanding the statistical concepts behind ARIMA can greatly enhance your ability to leverage this model effectively. AutoRegressive (AR) Component: The AR part of ARIMA signifies that the evolving variable of…
-
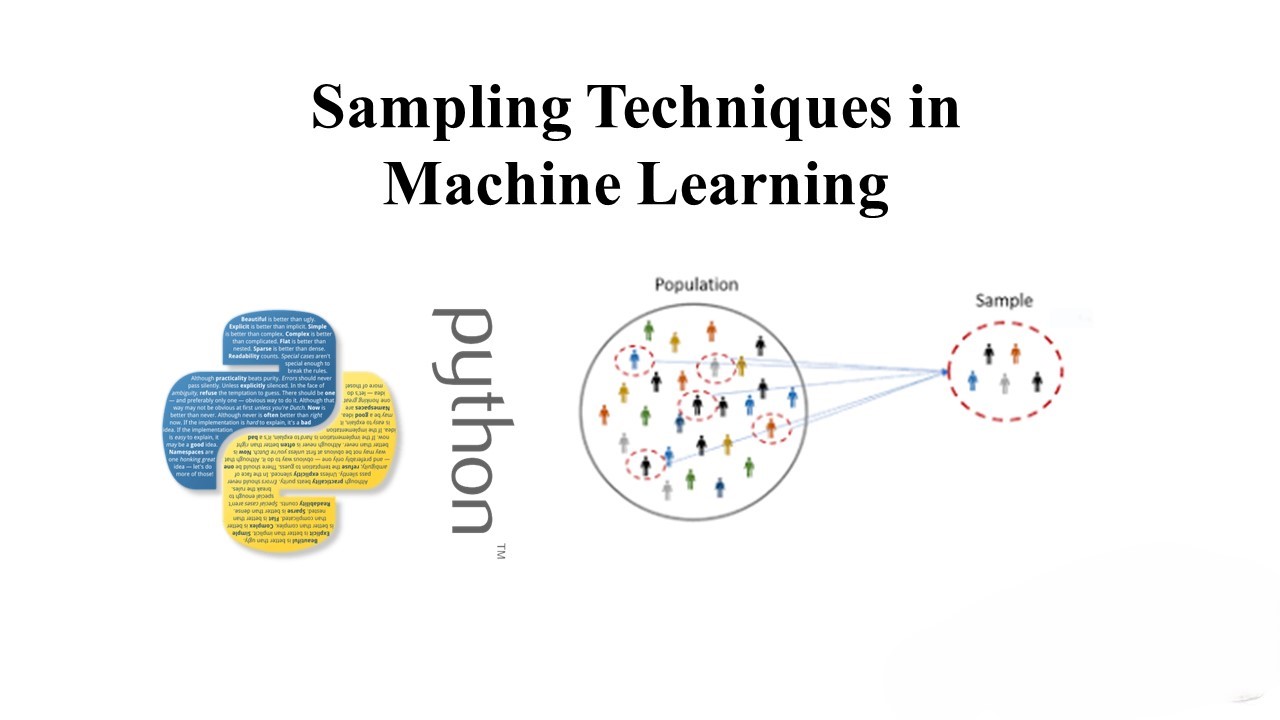
A Visual Guide To Sampling Techniques in Machine Learning
When working with large datasets, it’s often impractical to train machine learning models on the entire dataset. Instead, we opt to work with smaller, representative samples. However, the way we sample can significantly impact the performance and accuracy of our models. Let’s explore some commonly used sampling techniques: 🔹 Simple Random Sampling: Each data point…
-
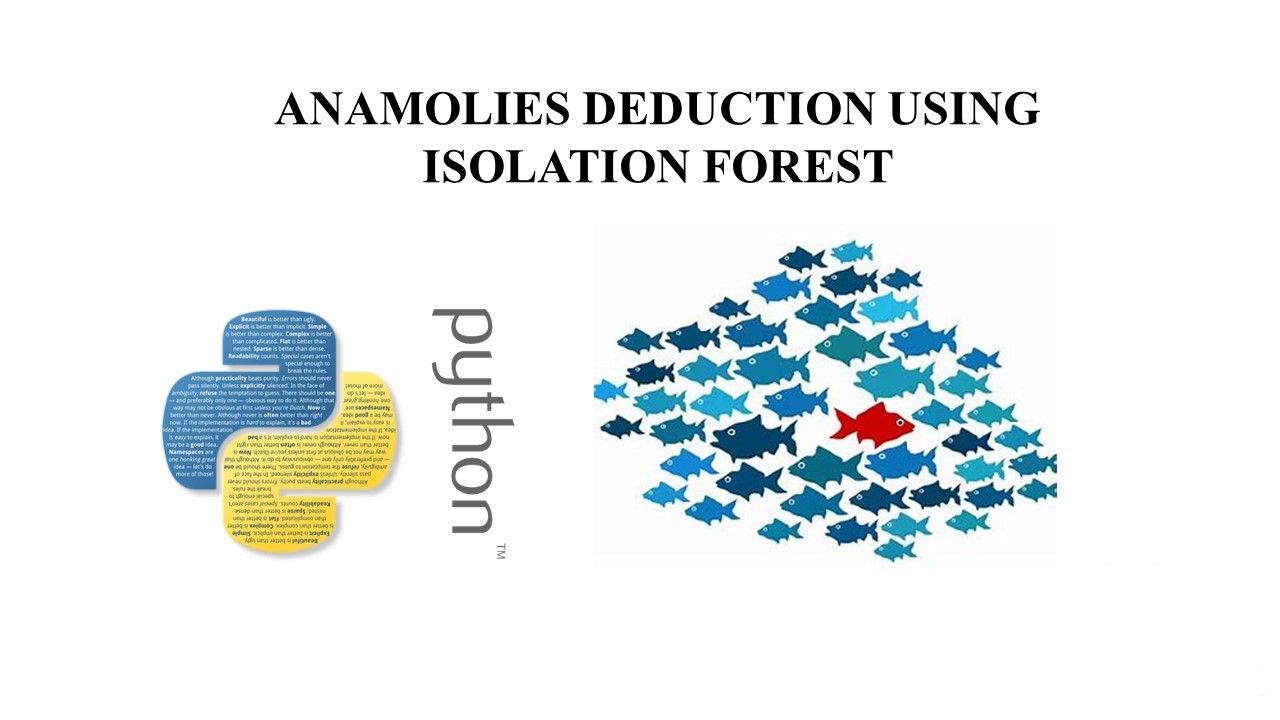
Unlocking Anomaly Detection: Exploring Isolation Forests
In the vast landscape of machine learning, anomaly detection stands out as a critical application with wide-ranging implications. One powerful tool in this domain is the Isolation Forest algorithm, known for its efficiency and effectiveness in identifying outliers in data. Let’s delve into the fascinating world of Isolation Forests and their role in anomaly detection.…
-

The Mathematics Behind Machine Learning
Machine learning is a branch of artificial intelligence that enables computers to learn from data and make decisions or predictions without being explicitly programmed. At the core of machine learning algorithms lie mathematical concepts and principles that drive their functionality. In this blog post, we’ll explore some key mathematical concepts behind machine learning. Linear Algebra…
-

Composite Estimators using Pipeline & FeatureUnions
In machine learning workflows, data often requires various preprocessing steps before it can be fed into a model. Composite estimators, such as Pipelines and FeatureUnions, provide a way to combine these preprocessing steps with the model training process. This blog post will explore the concepts of composite estimators and demonstrate their usage in scikit-learn (version…
-
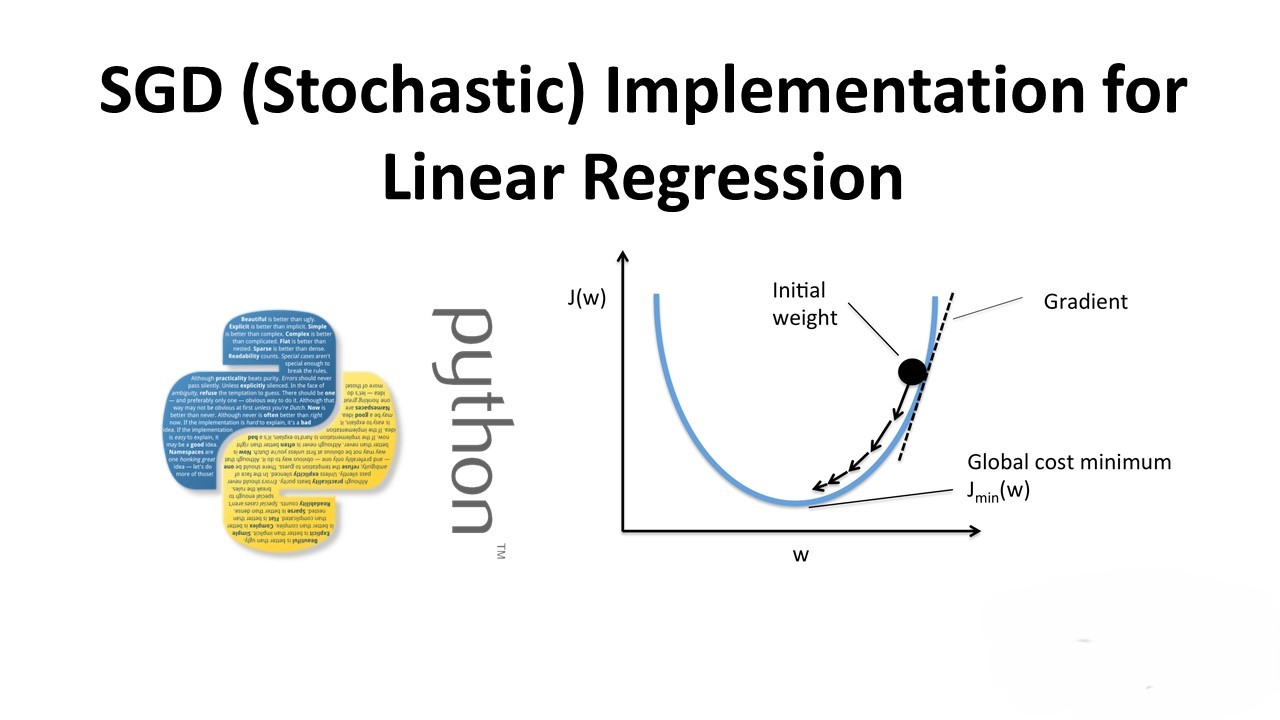
Custom SGD (Stochastic) Implementation for Linear Regression on Boston House Dataset
In this post, we’ll explore the implementation of Stochastic Gradient Descent (SGD) for Linear Regression on the Boston House dataset. We’ll compare our custom implementation with the SGD implementation provided by the popular machine learning library, scikit-learn. Importing Libraries Data Loading and Preprocessing We load the Boston House dataset, standardize the data, and split it…