Tag: #FeatureEngineering
-
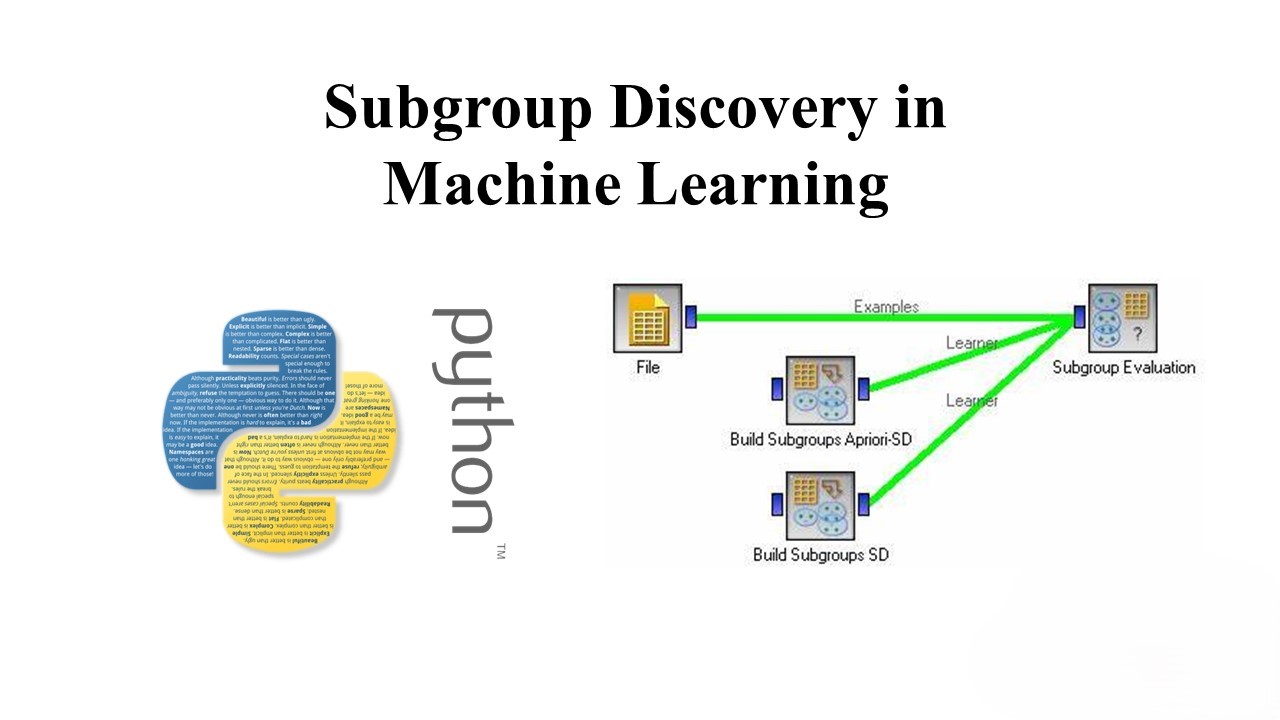
A Guide to Subgroup Discovery in Machine Learning
In the vast landscape of machine learning, uncovering hidden patterns in data is often the key to unlocking valuable insights. One powerful technique for achieving this is subgroup discovery, a method that focuses on identifying subsets of data that exhibit unique or interesting behavior. In this blog post, we’ll explore the concept of subgroup discovery…
-
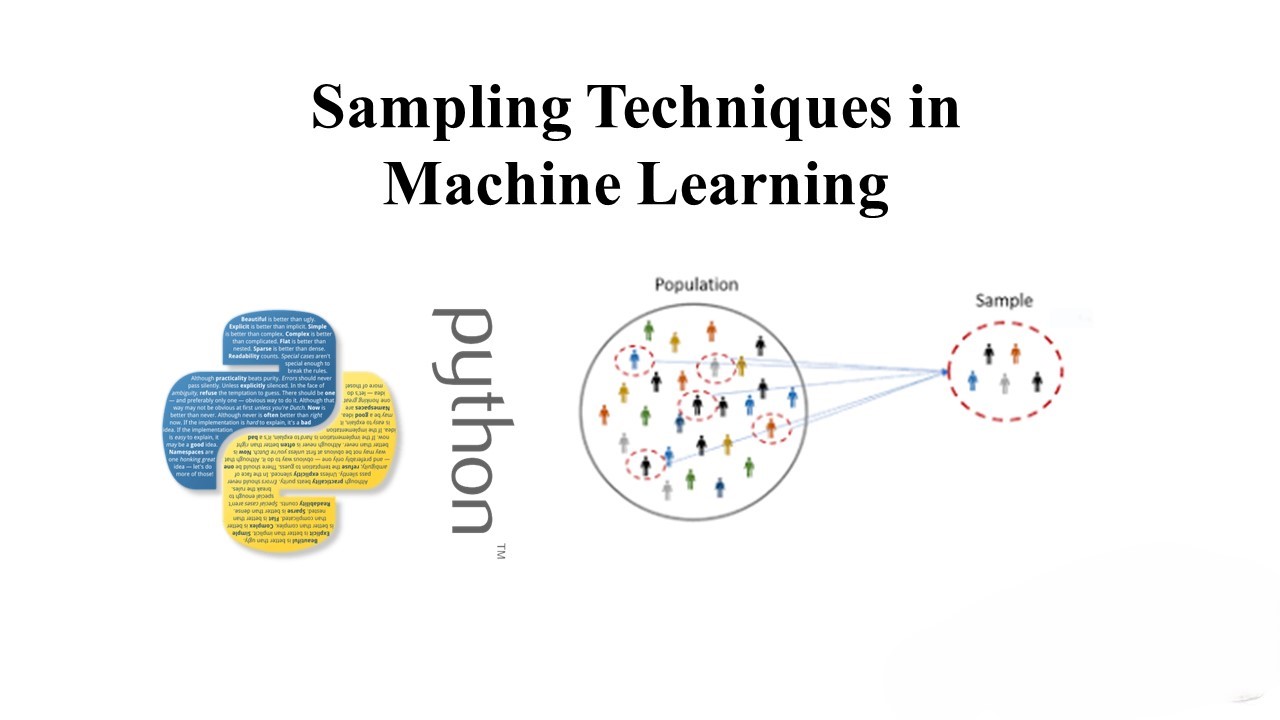
A Visual Guide To Sampling Techniques in Machine Learning
When working with large datasets, it’s often impractical to train machine learning models on the entire dataset. Instead, we opt to work with smaller, representative samples. However, the way we sample can significantly impact the performance and accuracy of our models. Let’s explore some commonly used sampling techniques: 🔹 Simple Random Sampling: Each data point…
-

The Mathematics Behind Machine Learning
Machine learning is a branch of artificial intelligence that enables computers to learn from data and make decisions or predictions without being explicitly programmed. At the core of machine learning algorithms lie mathematical concepts and principles that drive their functionality. In this blog post, we’ll explore some key mathematical concepts behind machine learning. Linear Algebra…
-
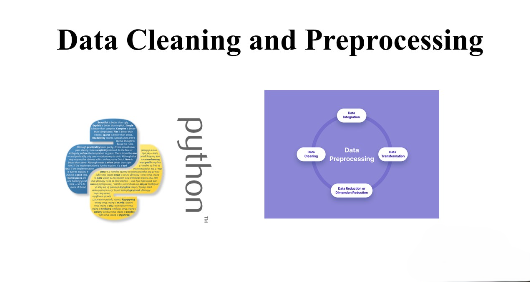
Data Preparation for Machine Learning
Data preparation is a crucial step in the machine learning pipeline. It involves cleaning, transforming, and organizing data to make it suitable for machine learning models. Proper data preparation ensures that the models can learn effectively from the data and make accurate predictions. Why is Data Preparation Important? Data preparation is essential for several reasons:…
-

Composite Estimators using Pipeline & FeatureUnions
In machine learning workflows, data often requires various preprocessing steps before it can be fed into a model. Composite estimators, such as Pipelines and FeatureUnions, provide a way to combine these preprocessing steps with the model training process. This blog post will explore the concepts of composite estimators and demonstrate their usage in scikit-learn (version…
-
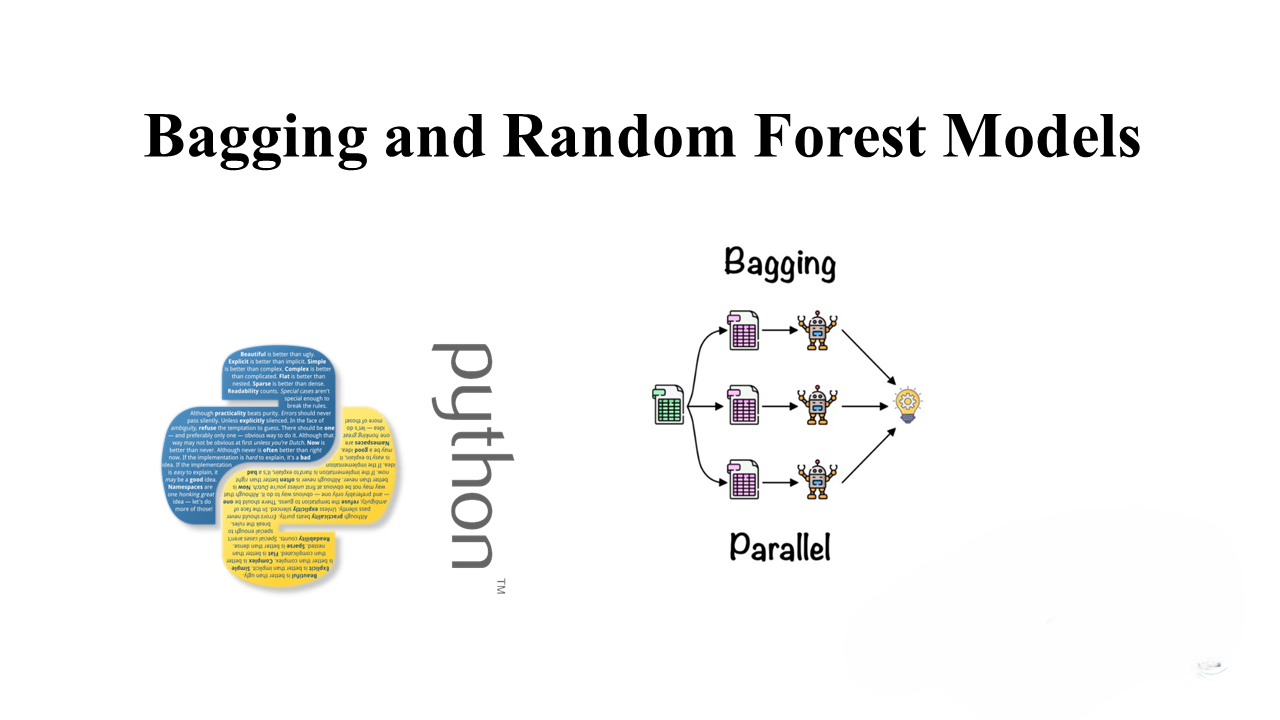
Understanding Bagging and Random Forest Models
Ensemble methods are powerful techniques that combine multiple weak learners to improve predictive performance. One popular ensemble method is bagging, which aggregates the predictions of multiple models trained on subsamples of the data. Random Forest, a widely used algorithm, employs bagging with decision trees to produce robust and scalable models. Introduction In this blog post,…
-
Exploratory Data Analysis and Market Basket Analysis with Python
In the realm of retail, understanding customer behavior and optimizing product offerings can be a game-changer. In this blog post, we’ll explore how to perform Exploratory Data Analysis (EDA) and Market Basket Analysis using Python, specifically focusing on a dataset related to retail transactions. Introduction The dataset we’re working with contains information about retail transactions.…
-
Conquering Python Tuples for Beginners and Beyond 🐍
In Python, a tuple is a versatile data structure that allows you to store ordered and immutable sequences of elements. In this exploration, we’ll delve into the characteristics, operations, and manipulation techniques associated with tuples. Understanding Tuples A tuple is defined by enclosing a sequence of Python objects in round brackets. It is comparable to…
-

Mastering Advanced Techniques for Python Dictionary Sorting
Dictionaries in Python are powerful data structures that allow you to store key-value pairs. Often, there arises a need to sort a dictionary based on its values. In this exploration, we’ll uncover the techniques to efficiently sort a dictionary in both ascending and descending order. Example Dictionary Object Let’s consider a sample dictionary to demonstrate…
-
Set Your Python Skills on Fire with the Power of Sets 😮
Sets in Python are a versatile and powerful data type that provide a unique way to store and manipulate collections of elements. In this exploration, we will delve into the fascinating world of sets, understanding their creation, modification, and various operations that can be performed on them. Creating Sets A set is a collection of…