Tag: #InformationExtraction
-

Visualizing NLP with Pretrained Models – spaCy and StanfordNLP
Natural Language Processing (NLP) is a crucial aspect of understanding and processing human language using computational methods. In this tutorial, we will explore two popular NLP libraries – spaCy and StanfordNLP – and demonstrate their capabilities using pretrained models. spaCy – English NLP Let’s start with spaCy and an English example. We’ll use a snippet…
-
Exploring Named Entity Recognition with Conditional Random Fields
Named Entity Recognition (NER) is a fundamental task in natural language processing that involves identifying and classifying entities, such as names of people, organizations, and locations, within a text. NER plays a crucial role in various applications, including information retrieval, question answering, and text summarization. In this blog post, we’ll dive into the world of…
-
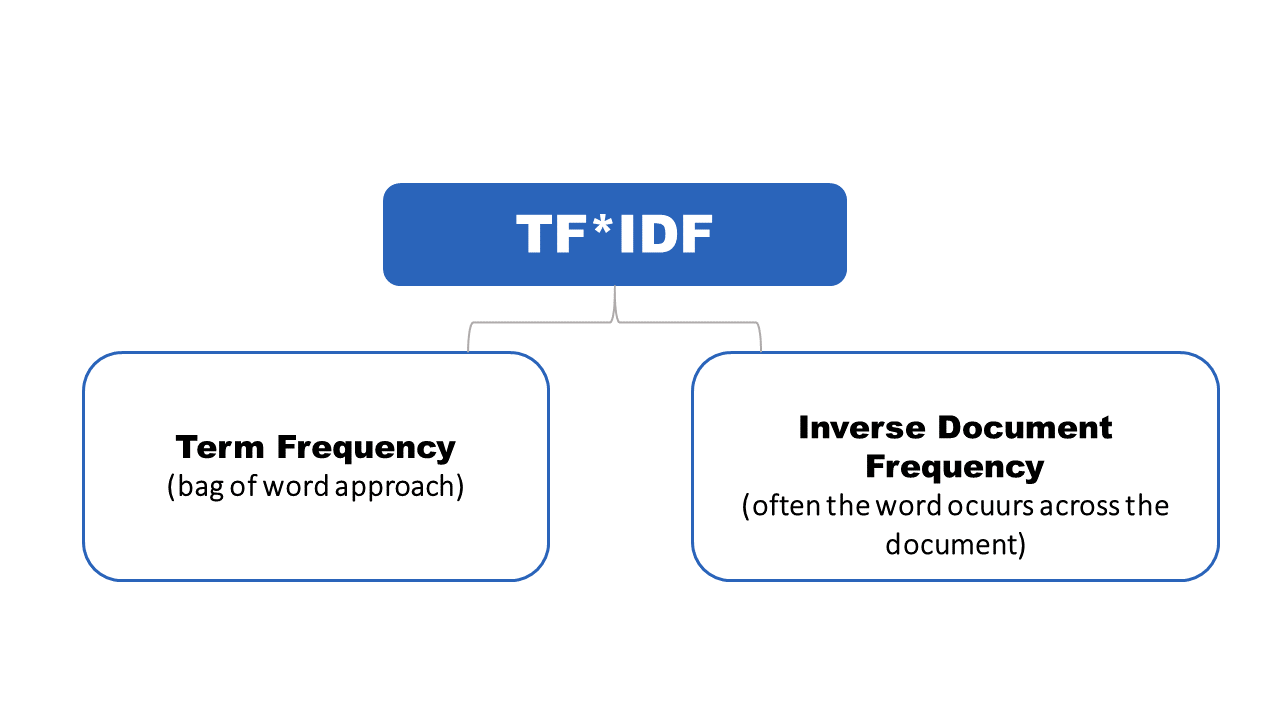
A Deep Dive into Text Classification with TF-IDF
Introduction: Unlocking the potential within textual data is a rewarding journey, and text classification, a cornerstone of Natural Language Processing (NLP), stands as a beacon in this exploration. In this blog post, we delve into the intricacies of text classification using Python, Pandas, NLTK, and scikit-learn. Our practical example revolves around travel and food-related sentences,…