Tag: #MachineLearning
-

Composite Estimators using Pipeline & FeatureUnions
In machine learning workflows, data often requires various preprocessing steps before it can be fed into a model. Composite estimators, such as Pipelines and FeatureUnions, provide a way to combine these preprocessing steps with the model training process. This blog post will explore the concepts of composite estimators and demonstrate their usage in scikit-learn (version…
-
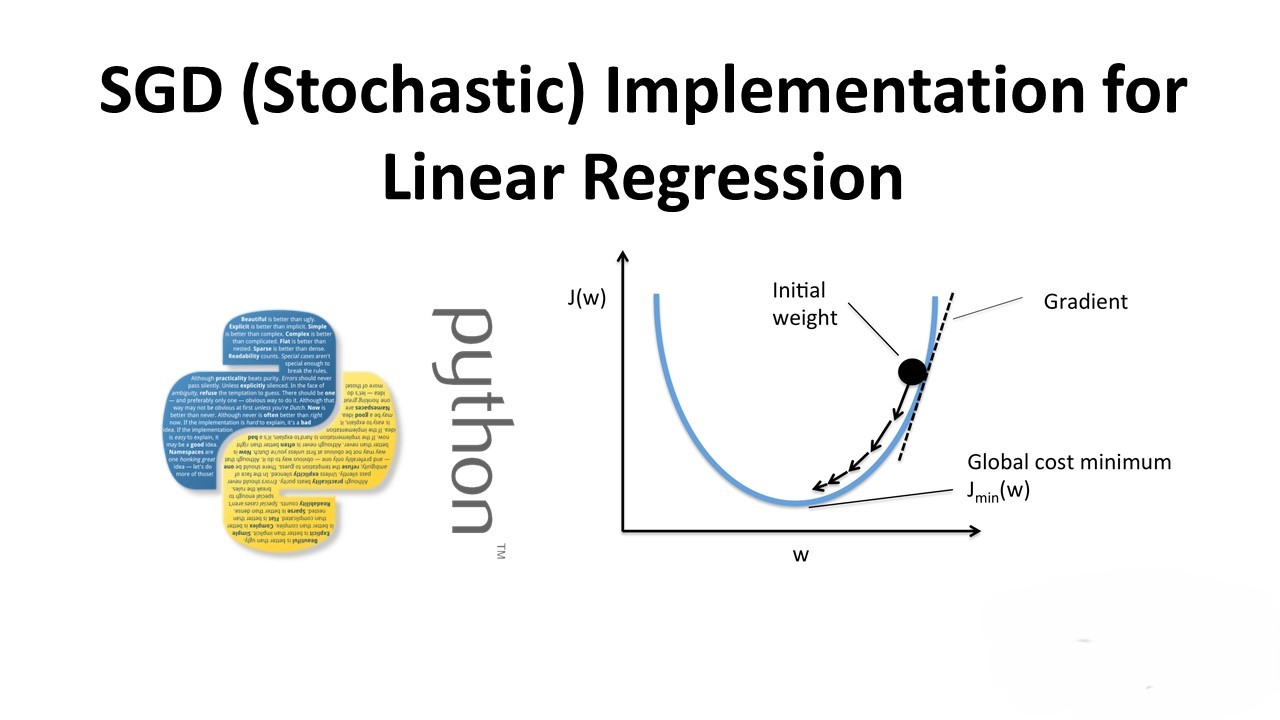
Custom SGD (Stochastic) Implementation for Linear Regression on Boston House Dataset
In this post, we’ll explore the implementation of Stochastic Gradient Descent (SGD) for Linear Regression on the Boston House dataset. We’ll compare our custom implementation with the SGD implementation provided by the popular machine learning library, scikit-learn. Importing Libraries Data Loading and Preprocessing We load the Boston House dataset, standardize the data, and split it…
-

Uncovering Shopping Patterns in a German Retail Store using Association Rules
In the realm of retail analytics, understanding customer behavior is key to improving sales and customer satisfaction. One powerful tool for this task is association rule mining, which can reveal interesting patterns in customer purchasing habits. In this blog post, we’ll explore how association rules can be applied to transaction data from a German retail…
-
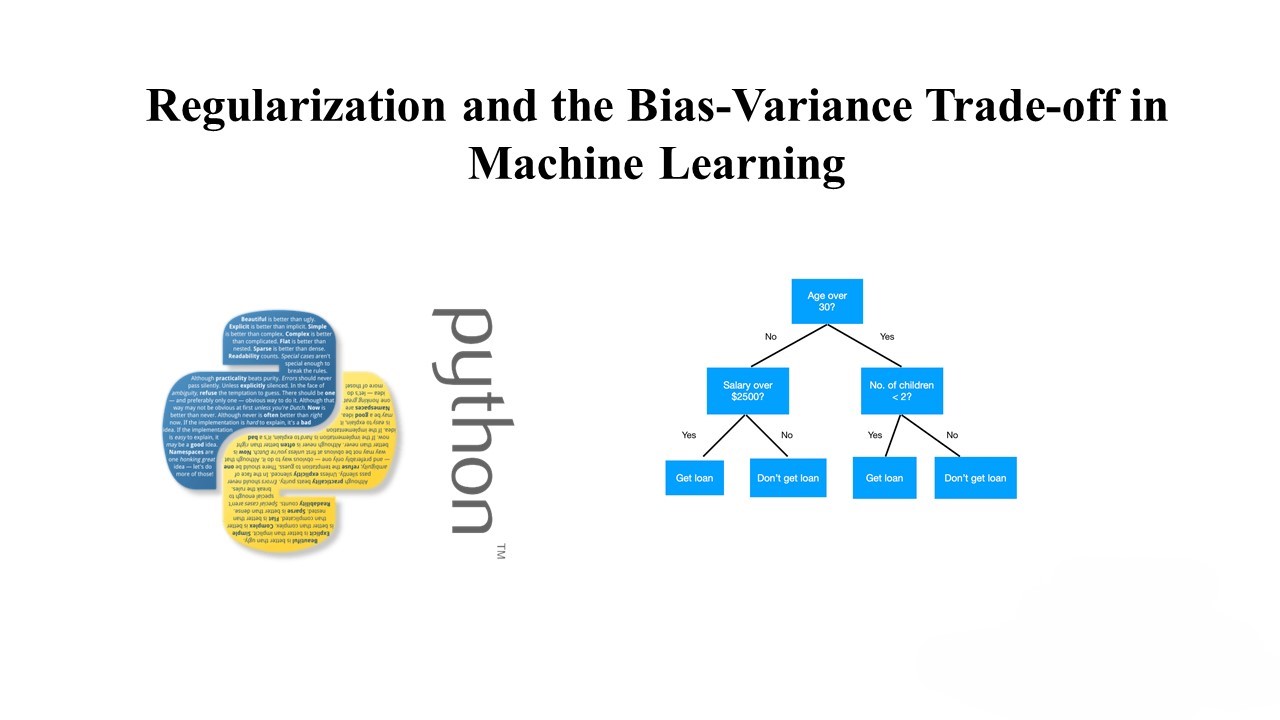
Understanding Decision Trees: A Comprehensive Guide with Python Implementation
Introduction: Decision trees are powerful tools in the field of machine learning and data science. They are versatile, easy to interpret, and can handle both classification and regression tasks. In this blog post, we will explore decision trees in detail, understand how they work, and implement a decision tree classifier using Python. What is a…
-
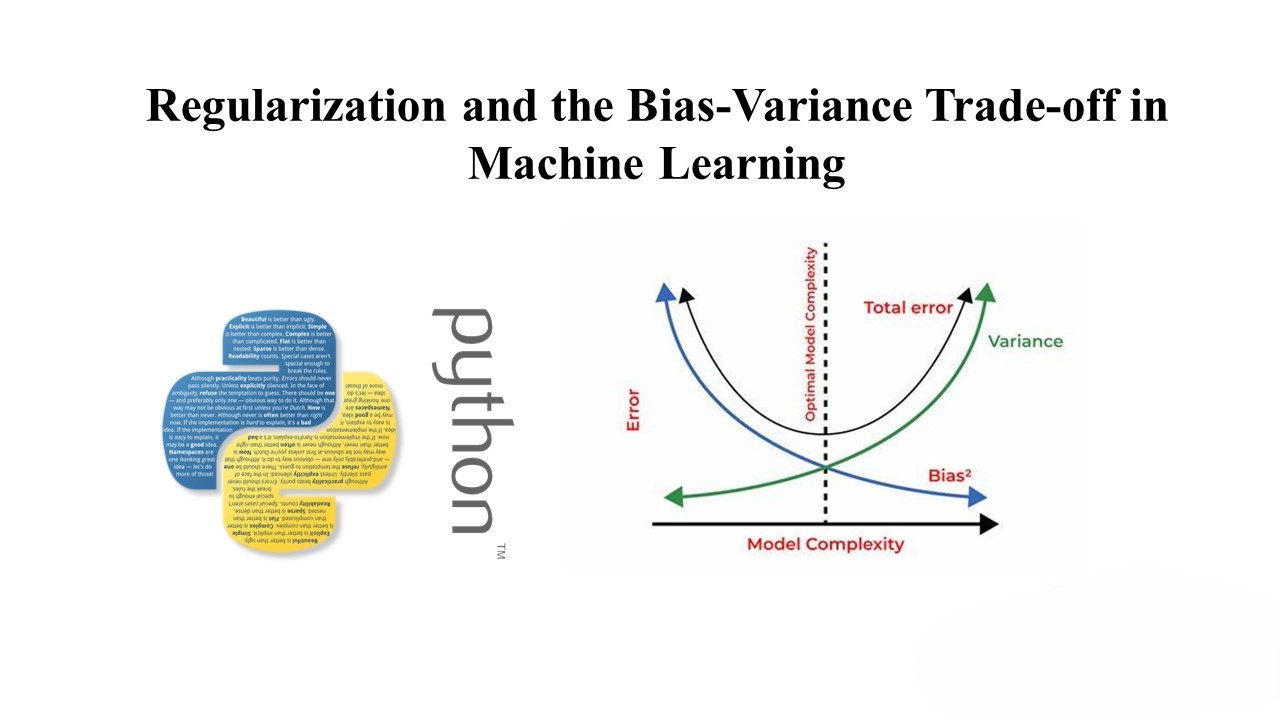
Regularization and the Bias-Variance Trade-off in Machine Learning
Overfitting is a common issue in machine learning models, where a model fits the training data too closely, leading to poor generalization on new data. Regularization is a technique used to prevent overfitting by adding a penalty term to the model’s loss function. This penalty encourages simpler models and helps strike a balance between bias…
-
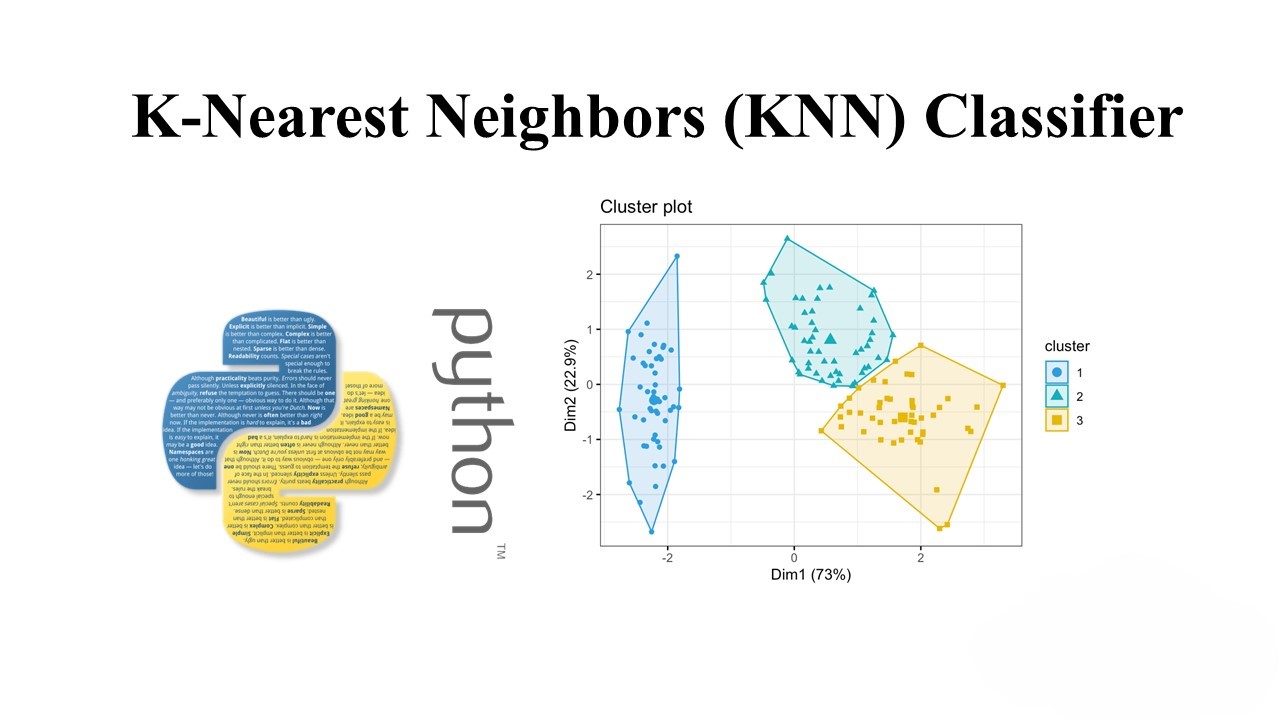
Understanding CIFAR-10 Dataset and K-Nearest Neighbors (KNN) Classifier
In this blog post, we’ll explore the CIFAR-10 dataset and how to use the K-Nearest Neighbors (KNN) algorithm to classify images from this dataset. CIFAR-10 is a well-known dataset in the field of machine learning and computer vision, consisting of 60,000 32×32 color images in 10 classes, with 6,000 images per class. Loading and Preprocessing…
-

Understanding Epochs in Neural Networks: A Comprehensive Guide
In this tutorial, we’ll dive deep into the concept of epochs in neural networks. We’ll explore how the number of epochs impacts training convergence and how early stopping can be used to optimize model generalization. Neural Networks: A Brief Overview Neural networks are powerful supervised machine learning algorithms commonly used for solving classification or regression…
-
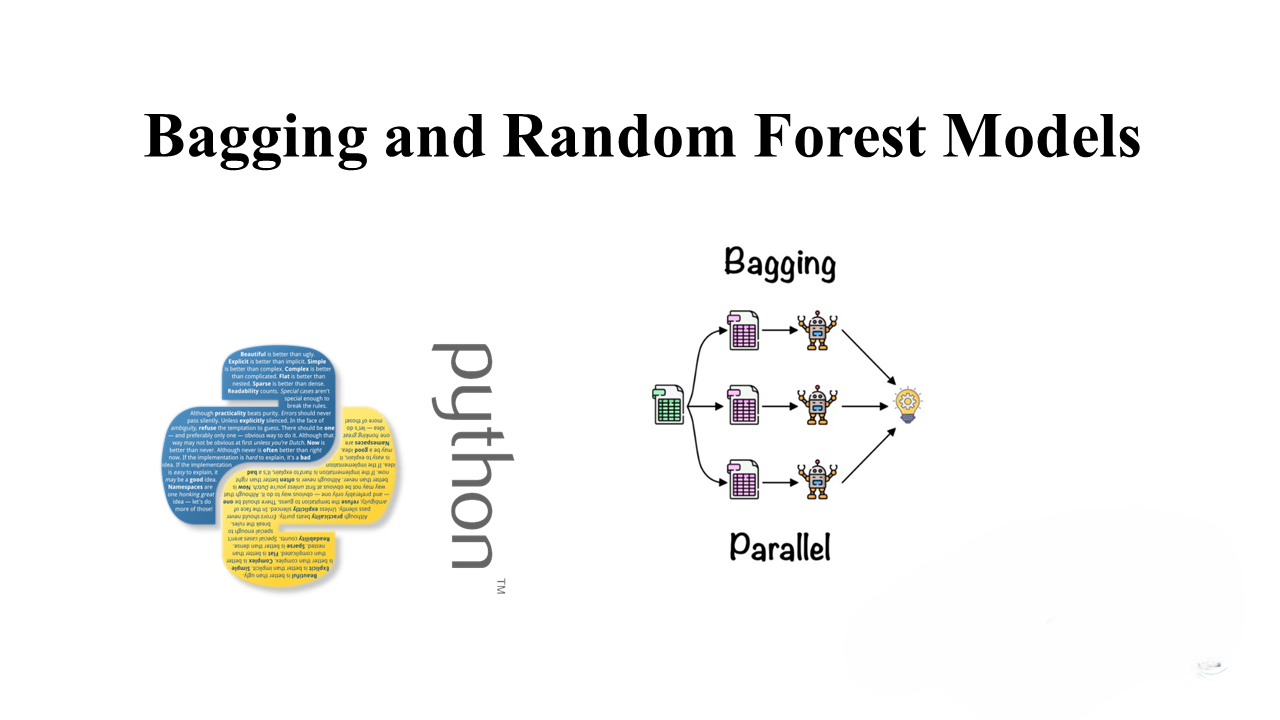
Understanding Bagging and Random Forest Models
Ensemble methods are powerful techniques that combine multiple weak learners to improve predictive performance. One popular ensemble method is bagging, which aggregates the predictions of multiple models trained on subsamples of the data. Random Forest, a widely used algorithm, employs bagging with decision trees to produce robust and scalable models. Introduction In this blog post,…
-
Mastering Linear Models: Regression, Classification, and Beyond
Introduction: Linear models play a fundamental role in the field of machine learning, providing a versatile toolkit for both regression and classification tasks. In this comprehensive guide, we’ll delve into various aspects of linear models, exploring techniques for regression, classification, and addressing challenges such as outliers and non-linear relationships. Buckle up as we journey through…
-

Unveiling the Power of Word Embeddings with Gensim
In the realm of Natural Language Processing (NLP), word embeddings have emerged as a game-changer. Unlike traditional approaches that use words as features, word embeddings leverage dense, low-dimensional vectors to capture the meaning and usage of a word. One pioneering model in this domain is Word2Vec, developed by Thomas Mikolov and team at Google. In…