Introduction:
Decision trees are powerful tools in the field of machine learning and data science. They are versatile, easy to interpret, and can handle both classification and regression tasks. In this blog post, we will explore decision trees in detail, understand how they work, and implement a decision tree classifier using Python.
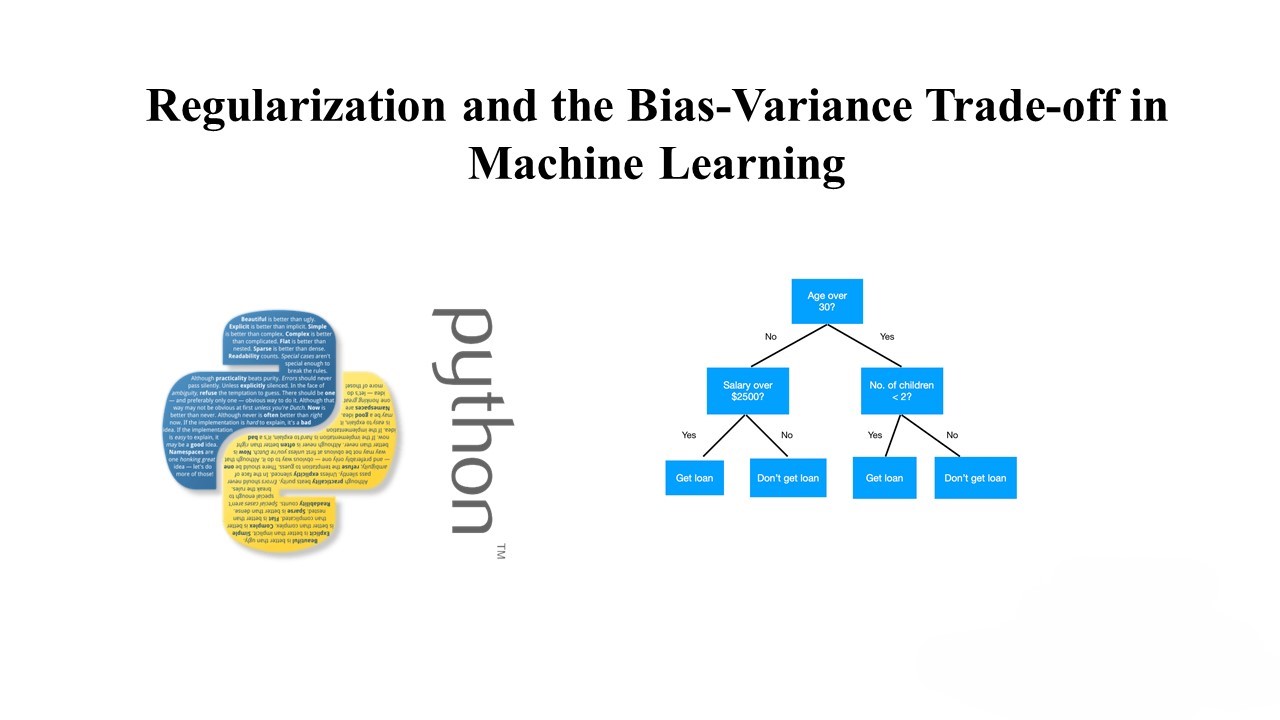
What is a Decision Tree? A decision tree is a tree-like structure where:
- Each internal node represents a “test” or “decision” on an attribute.
- Each branch represents the outcome of the test.
- Each leaf node represents a class label (in classification) or a continuous value (in regression).
How Does a Decision Tree Work?
- Tree Construction: The process starts from the root node and recursively splits the dataset into subsets based on the selected features.
- Feature Selection: The best feature to split on is selected using criteria such as Gini impurity, entropy, or information gain.
- Stopping Criteria: The tree continues to split until a stopping criterion is met, such as reaching a maximum depth, minimum number of samples per split, or purity threshold.
- Predictions: Once the tree is constructed, new data can be classified or predicted by following the decisions in the tree from the root to a leaf.
Implementing a Decision Tree Classifier in Python:
Let’s implement a decision tree classifier using the popular scikit-learn library in Python. We will use the Iris dataset for this example, which is a popular dataset for classification tasks.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Split the dataset into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Create a decision tree classifier
clf = DecisionTreeClassifier(random_state=42)
# Train the classifier on the training data
clf.fit(X_train, y_train)
# Make predictions on the test data
y_pred = clf.predict(X_test)
# Calculate the accuracy of the model
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
This code snippet demonstrates how to load the Iris dataset, split it into training and test sets, create a decision tree classifier, train the classifier, make predictions, and calculate the accuracy of the model.
Conclusion:
Decision trees are powerful and intuitive models for both classification and regression tasks. They are easy to interpret and can handle both numerical and categorical data. However, they are prone to overfitting, especially with deep trees. Techniques like pruning, setting a maximum depth, or using ensemble methods like Random Forest can help mitigate this issue.
In this blog post, we’ve covered the basics of decision trees, their construction, and implementation in Python using scikit-learn. I hope this has provided you with a solid understanding of decision trees and how to use them in your machine learning projects.
Leave a Reply